.png)
Executive Summary
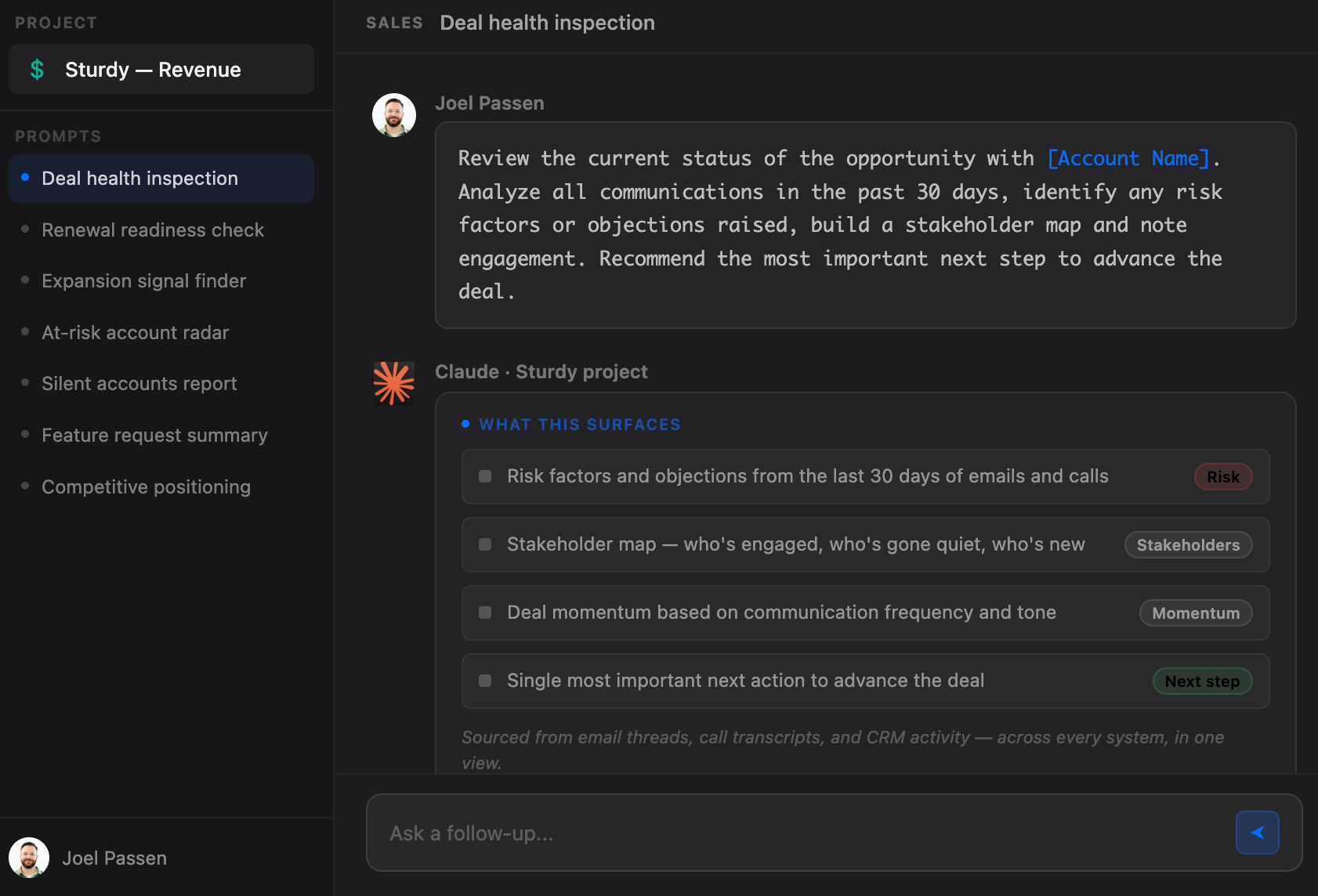
The Context Engine
The model is not the problem. In every enterprise AI deployment that has hit a production wall in 2026, the failure lives one layer down: in how data is prepared, permissioned, and delivered before the model ever begins reasoning. Model choice has become the wrong question. With Anthropic's Claude surpassing OpenAI in U.S. enterprise adoption (34.4% vs. 32.3%, Ramp AI Index, April 2026), the market has already moved on. The competition has shifted from the Reasoning Engine to the Context Engine.
While nearly every enterprise has deployed frontier models, most are paying a Hallucination Tax they cannot see on their P&L. For an organization with 1,000 knowledge workers, the 4.3 hours per employee per week spent manually verifying AI outputs (Forrester, 2025) equates to approximately $16.8 million in annual salary drain, calculated at a conservative $75 per fully-loaded hour. Multiply that across a global enterprise, and it maps to the $67.4 billion in documented AI hallucination losses recorded in 2024 alone (AllAboutAI, 2025). This is not a failure of the model. It is a failure of architecture.
This paper argues that the next phase of enterprise AI requires a Deterministic Intelligence Layer: infrastructure that normalizes, indexes, and permissions customer data before it reaches the model. Teams replacing token-heavy RAG workflows with deterministic, pre-indexed context are seeing substantial reductions in cost per task while dramatically improving retrieval precision and AI reliability. More importantly, they are crossing the Threshold of Action: the point where AI becomes trustworthy enough to move from surfacing insights to executing workflows.

Section 1
The New Benchmark: Claude's Enterprise Breakout Moment
The AI market just had its crossover moment. As of April 2026, more U.S. businesses pay for Anthropic's Claude than for any other AI model. 34.4% vs. 32.3% for OpenAI, according to the Ramp AI Index, which tracks actual spending across more than 50,000 companies. This isn't a survey about intent. It's purchasing data.
By March 2026, Anthropic was capturing 73% of first-time business AI buyers (Axios, March 2026). A year earlier, one in 25 businesses on Ramp's platform paid for Anthropic. Today, it's nearly one in three.
Enterprise buyers don't switch defaults on a whim. They switch when something is demonstrably working better for the work they actually need done.
The Model Is Not the Problem
Here is the harder truth underneath that adoption story. Despite the crossover, most enterprise AI deployments are not delivering.

Widespread adoption. Widespread underdelivery. Both things are true simultaneously.
The instinct in most organizations is to treat this as a model problem: switch providers, upgrade to the latest version, hire a prompt engineer. None of it moves the needle in any sustained way, because the model is not where the failure lives. Claude is a reasoning engine. A sophisticated one. But a reasoning engine can only reason over what it's given. And in most enterprise deployments, what's given is a mess. Fragments.
The Performance Ceiling
Every technical leader deploying Claude at scale hits the same wall. The demo works. The pilot looks promising. Then it moves toward production, and something breaks. Not catastrophically, but consistently. The AI misattributes an item to the wrong account. It summarizes a customer's history using stale data. It generates an output that sounds authoritative and requires 20 minutes of human verification before it can be trusted.
"Feed a world-class reasoning engine confident, well-structured garbage, and you get the same in return."
This is not a failure of reasoning capability. It is a failure of context architecture. The data required to generate reliable outputs, account history, communications, support activity, call transcripts, and operational metadata typically exists across fragmented systems with inconsistent normalization, disconnected permissions, and no canonical entity resolution layer tying it together.
Context Is the New Infrastructure
The companies pulling ahead in 2026 are not winning because they chose a better model. They are winning because they solved the harder problem underneath it: delivering clean, resolved, permission-aware context before the model ever begins reasoning.
- IT, Data, and Platform Engineering provide the Engine (Claude): a recurring operating expense. World-class reasoning, rented.
- RevOps, Data, and AI Teams provide the Map (the Deterministic Data Layer): a long-term asset. Customer intelligence, owned.
Claude is the current catalyst. The model market will keep moving. New releases, new providers, new pricing. What doesn't move is the underlying problem: fragmented, unresolved, improperly permissioned data. Deterministic context is the durable architecture. The organizations building it now will carry that advantage into every subsequent model generation.
Most organizations already have the engine. What they lack is the map.
Section 2
The Hallucination Tax: Why Fragmented Data Kills AI Performance
If the model isn't the problem, why are so many production-grade AI initiatives hitting a performance ceiling? The answer is the Hallucination Tax.
In 2024, hallucinations cost enterprises an estimated $67.4 billion in global losses (AllAboutAI, 2025). By early 2026, the cost has shifted from outright fabrications to "silent hallucinations": outputs that look structurally perfect but are factually untethered from the current state of the business.
For an organization with 1,000 knowledge workers, the 4.3 hours lost per person per week equates to roughly 223,600 hours of wasted annual productivity, approximately $16.8 million in annual salary drain at a conservative, fully loaded rate. It never appears on the P&L as an AI cost. It shows up as underperformance, missed forecasts, and slower deal cycles.

This forces employees to act as "Human Middleware": the bridge between fragmented systems and the AI that was supposed to make them irrelevant. This tax is the direct result of four specific architectural failure modes.
Failure Mode 1: Retrieval Precision (The Token Tax)
Standard RAG is probabilistic. It retrieves semantically similar fragments, not operational truth. When a sales leader asks, "Why did we lose this seven-figure deal?", the system may surface an old QBR deck instead of the pricing objections in email, the procurement concerns buried in Slack, the legal escalation in Jira, and the product gaps discussed in call transcripts that actually determined the outcome.
Because retrieval is imprecise, teams over-index by stuffing the context window with every possible document to ensure the right one is in there. The result: thousands of reasoning tokens spent filtering noise. A world-class reasoning engine doing the work of a search index.
Failure Mode 2: "Lost in the Middle" (Attention Drift)
Research by Liu et al. (TACL, 2024) demonstrated that accuracy on multi-document reasoning tasks drops by more than 30 percentage points when relevant information is buried in the middle of a long context window. This matters enormously in enterprise environments, where critical signals are scattered across support escalations, pricing discussions, call transcripts, Slack threads, and CRM updates. Simply increasing context size does not solve the problem. In many cases, it amplifies it by forcing the model to attend to more noise.
Failure Mode 3: The Identity Crisis (Entity Disambiguation)
In a fragmented environment, identity is a variable, not a constant. "Jane Doe" in a Zoom transcript needs to resolve to the same Jane Doe in Salesforce, Gmail, Zendesk, Slack, and the CRM activity timeline. Without deterministic entity resolution, the model is forced to infer whether those interactions belong to the same person, account, or buying committee.
Without deterministic entity resolution, the model is forced to reconstruct identity probabilistically. A support escalation tied to one stakeholder, a pricing objection raised in a sales call, and an executive concern discussed over email may be incorrectly assembled into the wrong account narrative entirely.
Failure Mode 4: The Permission Ghost (Unauthorized Surface)
This is the silent killer of enterprise AI programs. Most RAG pipelines lack Source-System Parity. If the AI retrieves a snippet from a private executive email because it was "semantically relevant" to an intern's query, the system has failed regardless of whether anyone noticed.
Incidents like EchoLeak show exactly why retrieval-layer permission enforcement matters. In late 2025, researchers demonstrated a zero-click vulnerability in Microsoft 365 Copilot that could exfiltrate sensitive data from Copilot context without user interaction. No prompt injection required. The retrieval layer was the attack surface.
For most organizations, the permission layer isn't just a technical problem. It is an organizational liability that Legal and Security will eventually force you to solve on a deadline, under pressure, after something has already gone wrong.
The Production Wall
These four failure modes create the Production Wall. A curated demo can appear remarkably accurate. But production environments are not curated. They are noisy, fragmented, and constantly changing, with critical signals distributed across emails, calls, support threads, Slack conversations, and operational systems evolving in real time.
"You cannot solve these four problems by tuning the prompt. You have to solve them by fixing the context."

Section 3
The Deterministic Intelligence Layer
To climb over the Production Wall, enterprise architecture must evolve. The solution is not a larger context window or a more complex prompt. It is a fundamental shift in how data is prepared for the model. Enter the Deterministic Intelligence Layer: infrastructure that sits between your raw data silos and Claude, acting as the architectural antidote to the four failure modes in Section 2.
The Four Pillars
1. Precision Indexing (Ending the Token Tax)
Instead of relying on similarity search alone, the context layer resolves entities, removes duplication, and prioritizes high-signal interactions before retrieval. The model receives structured operational context rather than raw fragments competing for attention.
In Sturdy-observed deployments, replacing raw context with pre-indexed, distilled payloads has reduced token consumption by 80 to 90% on comparable workflows. Results vary by source data density and baseline architecture. You stop paying for Claude to be a search filter.
2. Signal Distillation (Solving "Lost in the Middle")
Semantic Pruning strips HTML headers, Slack noise, legal footers, and the RE: FWD: RE: reply chains that bury every actual decision in 40 lines of quoted text, distilling threads into thematic buckets: Bug Reports, Feature Requests, Sentiment Shifts. The most critical insights land at the beginning of the context window, bypassing the 30-point accuracy drop documented in long-context research.
3. Deterministic Entity Resolution (Fixing the Identity Crisis)
A Global Entity Map resolves disparate naming conventions into a single, immutable Customer ID. Claude is no longer guessing whether two conversations belong to the same account. It is being told they do.
4. Parity-Enforced Permissions (Exorcising the Permission Ghost)
The retrieval layer enforces source-system permissions before context assembly, so unauthorized records are excluded from the payload sent to the model. This is not a prompt-level instruction that can be overridden or confused. It is an architectural enforcement point that sits entirely upstream of the model.
Security becomes a structural property of the architecture, not a probabilistic instruction to the model. Incidents like EchoLeak show why this distinction matters: when permission logic lives inside the prompt, the retrieval layer remains an attack surface. When it lives at the data layer, it doesn't.
Reference Implementation: Sturdy + Claude via MCP
While the merits of this architecture are clear, building it internally results in years of maintenance debt (see Section 5). Sturdy leverages the Model Context Protocol to serve as the Context Engine for Claude, normalizing, indexing, and permission-stamping your customer intelligence layer across Salesforce, Gmail, Slack, and Zendesk before Claude ever queries it.
Claude provides the Reasoning Layer. Sturdy provides the Memory and Context Layer. Together, they move an enterprise from AI that reads your business to AI that acts on it.

Section 4
What It Unlocks: From Reading to Acting
In 2026, summarization is a commodity. The competitive advantage lies in moving from AI that reads your business to AI that acts on it. This transition requires a fundamental shift in how leadership views the AI stack and who owns what.
- IT, Data, and Platform Engineering provide the Engine (Claude): recurring operating expense. World-class reasoning, rented.
- RevOps, Data, and AI Teams provide the Map (the Deterministic Data Layer): a long-term asset. Customer intelligence, owned, not rented.
When the engine has a perfect map, the Acceleration Gap closes.
RevOps: The Revenue Architect
For the RevOps leader, a deterministic layer turns fragmented operational data into active revenue signals. Instead of building static dashboards that explain why a quarter was missed, RevOps can monitor the commercial signals that actually move deals: pricing hesitation in email, procurement delays, legal friction, competitive mentions, executive disengagement, stalled next steps, and tone changes across active opportunities.
A deterministic context layer resolves those signals to the right person, account, opportunity, and timeline before AI ever reasons over them. That is what turns scattered communication into reliable revenue action.
RevOps stops being a report generator. It becomes the operating system for revenue execution: designing the logic that turns verified commercial signals into coordinated GTM action.
Sales: Instant Account Intelligence
The average sales rep spends roughly 20% of their week on pre-call research. With a deterministic layer, the account briefing is no longer a probabilistic summary. It is a verified snapshot: "The customer's last three support tickets were resolved, but they haven't yet implemented the API update discussed in the March QBR."
Product: The Automated Feedback Loop
Product managers are often the most data-rich but insight-poor employees in the company. A deterministic layer moves PMs from reading feedback to querying insights. Claude analyzes 60 days of feedback across Slack and Zendesk and, with a single prompt, generates a high-fidelity Jira ticket including exact customer quotes, impacted account IDs, and revenue at risk.
Customer Success: Proactive Triage
In CS, latency is the enemy. A deterministic layer allows Claude to perform live triage. When a customer sends a frustrated email, the AI checks contract terms and recent product usage logs before the CSM has finished reading the subject line. It presents a Context-Aware Response ready to send, grounded in verified account data.
"The model you license today is rent. The customer intelligence layer you build is equity. One gets replaced. The other compounds."
Every account signal normalized, every entity resolved, every permission enforced. That accumulates. The organizations building this layer now are building institutional memory that makes every model they run on top of it better.

Section 5
The Build vs. Buy Reality
The instinct for most sophisticated IT and data teams is to build. It is a legitimate impulse. The stack looks deceptively simple: a few API connectors, a vector database, and some chunking logic. In the demo phase, an internal build often feels like the most cost-effective path.

The Four Hidden Engineering Hurdles
1. The Normalization Treadmill
Building a connector to Salesforce is straightforward. Maintaining the logic layer that resolves entity names across Salesforce, Slack, and Zendesk as those systems' schemas evolve is a full-time engineering job. This is Semantic Drift: hundreds of developer hours consumed by maintenance rather than innovation.
2. The Permission Mapping Paradox
Mapping row-level permissions from source systems into an AI context window is one of the most complex security challenges in modern software. Most internal builds rely on prompt-level security, which fails under the weight of incidents like EchoLeak. This isn't a technical trade-off. It is an organizational liability waiting to be forced into crisis.
3. The Latency Wall
A custom RAG pipeline often takes 5 to 10 seconds to fetch and clean data. In Sturdy-observed deployments, pre-indexed deterministic retrieval consistently operates under 1 second on production data volumes, but reaching that benchmark requires specialized search infrastructure expertise that is rarely the core competency of a generalist data team building from scratch.
4. The Token Optimization Tax
Without signal distillation, internal builds routinely pass 3x to 5x more tokens than necessary. Teams save on build costs only to spend twice as much on model API costs.
Where Does Your Engineering Dollar Go?
The strategic question isn't "Can we build this?" It's "Should we own the maintenance of this?"

Competitive advantage does not live in the plumbing. No customer chooses a vendor because their AI has a better Python script for cleaning Slack data.
By offloading the Normalization Treadmill to Sturdy, organizations are promoting their engineering teams from Data Cleaners to AI Product Owners, moving their best people away from the maintenance treadmill and toward the high-value work of building AI that drives revenue.
Buy the plumbing. Build the logic. The teams doing this are shipping revenue-generating AI workflows, while their competitors are still debugging entity-resolution scripts.
Section 6
What to Do Now: The 2026 Roadmap
The Acceleration Gap is not a permanent state. It is a choice of architecture. The move is not to wait for a smarter model. The move is to fix the context. Here are four moves for leadership to take in the next 90 days.
Move 1: Audit Your Retrieval Precision, Not Your Prompts
Most teams spend the majority of their time prompt-tuning errors caused by bad data retrieval. The action: Run a Ground Truth test. Take ten complex customer queries and manually check the data fragments Claude is being fed. If more than 20% of that data is noisy, stale, or misattributed, no prompt engineering will save the deployment. You have a plumbing problem, not a reasoning problem.
Move 2: Isolate a Multi-Source Workflow
The highest ROI for a deterministic layer is found where data is most fragmented. The action: Pick a high-value, closed-loop use case where data lives in at least three systems. For example: the path from customer feedback in Slack and Zendesk to an engineering action in Jira. Solve the context problem here, and you've built a blueprint for the rest of the organization.
Move 3: Enforce Permissions at the Data Layer
Stop treating security as a probabilistic instruction. The action: Move permission enforcement out of the system prompt and into the retrieval infrastructure. Ensure the retrieval layer enforces source-system permissions before context assembly, so unauthorized records never reach the model. The Permission Ghost is exorcised structurally, not instructionally, and the organizational liability is removed before Legal ever has to get involved.
Move 4: Define Where AI Earns the Right to Act
The distance between AI that summarizes and AI that executes is a trust gap, not a technology gap. The action: Build human-in-the-loop approval gates for high-stakes actions. Drafting a renewal contract. Creating a Jira ticket. Sending a support response. Use your deterministic layer to provide the required Confidence Equity. The threshold to target is a sub-5% error rate on AI-generated drafts. That is the point at which approval gates can be safely reduced, and workflows become self-sustaining.
Traditional probabilistic RAG architectures struggle to reach this threshold consistently at enterprise scale. Because probabilistic retrieval introduces entity errors, stale data, and permission noise, error rates on complex multi-source tasks typically stabilize in the 15 to 30% range regardless of prompt quality, even with hybrid retrieval and reranking layers added on top.
A deterministic layer that resolves entities before inference, distills the signal before retrieval, and enforces permissions before the model ever sees the data is the only architecture that makes sub-5% structurally achievable, rather than an occasional lucky outcome.
In Sturdy-observed deployments, teams that reach this threshold have consistently moved to reduced-oversight approval workflows within a quarter. Results depend on workflow complexity and baseline data quality. Reaching the sub-5% Trust Threshold is the definitive signal that an organization has graduated from "AI Experiments" to a Context Engine architecture capable of autonomous action. That is the architectural line between AI that assists and AI that acts.

Conclusion
The Architectural Advantage
Frontier models will continue to improve and commoditize. The durable advantage is no longer the model itself. It is the architecture surrounding it.
The long-term value does not live in another standalone AI interface. Interfaces change too quickly. The durable layer is the operational context infrastructure beneath them.
Organizations that solve deterministic context assembly, entity resolution, permission-aware retrieval, and operational state assembly gain a compounding advantage independent of whichever model, interface, or orchestration layer dominates next year.
Organizations that solve context architecture today are building infrastructure that compounds across model generations. As interfaces evolve and models improve, the operational context layer beneath them becomes increasingly valuable.
"The era of the Context Engine is here. Is your architecture ready for it?"



.png)