§ 1: The Setup
More signal, less action
Revenue teams have never had access to more AI-generated output. Intent signals, engagement scores, pipeline risk flags, account summaries generated from CRM data, recommended next actions populated into dashboards before the morning standup. The tools are proliferating. The outputs are multiplying. And yet, in most enterprise GTM organizations, the conversion from AI insight to actual decision is stagnating or declining.
The default diagnosis is a model problem or a product problem. The model is not accurate enough. The tool is not integrated deeply enough. The outputs are not surfaced in the right workflow. These are real friction points, but they are not the root cause. Fixing them at the application layer produces better-looking noise, not better decisions.
The actual problem is architectural, and it sits one layer below the model. Enterprise revenue data arrives fragmented: the same account exists as four different entities across Salesforce, Gong, HubSpot, and Zendesk. Engagement signals carry different timestamps, different field schemas, different definitions of what counts as a meaningful interaction. Permissions are enforced inconsistently, or not at all, before context reaches the model. When the model reasons over this, it is not reasoning over your business. It is reasoning over a probabilistic reconstruction of your business, assembled at runtime from inputs that contradict each other.
The result is outputs that teams cannot validate, cannot trace, and eventually stop trusting. The insight-to-action gap is not a UX problem. It is a data preparation problem that most organizations have not yet named correctly.
None of these data problems are new. Revenue systems have been fragmented for decades. What changed is that analysts used to perform the reconciliation manually. AI systems consume context directly. Every unresolved identity, duplicated record, and permission inconsistency that once slowed down an analyst now becomes part of the model's reasoning process. The rise of AI did not create the context problem. It exposed it.
Core argument: When the context layer is broken, no model is accurate enough. When it is built correctly, model selection becomes a secondary decision.
§ 2: Failure Patterns
Three failure patterns revenue teams actually recognize
The breakdown follows predictable patterns. Understanding the mechanism behind each one clarifies why application-layer fixes keep failing to address them.
Too many signals, no resolution. Modern GTM stacks produce a high volume of engagement data: web activity, intent signals, email opens, CRM updates, product usage events, support tickets. The problem is not the volume. The problem is that the same customer arrives as multiple disconnected records, each carrying a fragment of a complete picture. When retrieval pulls context for a model to reason over, it assembles a window full of candidates that may represent the same entity under four different identifiers. The model filters and weighs this noise because nothing upstream resolved it. That filtering costs tokens, introduces error, and produces outputs with confidence levels that cannot be verified against a ground truth. Teams receive a prioritization recommendation that reflects the quality of the retrieval, not the reality of the account.
Scores that cannot be traced. A high-priority account flag, a churn risk score, a pipeline confidence number. These outputs only change behavior if the team receiving them can validate the reasoning. When the underlying signals are fragmented, duplicated, or sourced from systems with inconsistent definitions, the model's output is not traceable to a specific set of inputs. The recommendation is real, but the path from data to conclusion runs through a retrieval process no one can inspect. Teams hesitate, override, or ignore, not because the model is wrong, but because they have no way to confirm it is right. Explainability is a function of what the model received, not just how it reasoned.
Insights that do not survive the handoff. Revenue organizations run across systems. Marketing works in attribution platforms. Sales lives in CRM. RevOps reconciles both. An AI output generated in one system rarely arrives intact in another, because the entity it references does not have a consistent identity across those systems. The account that marketing flagged as highly engaged is not the same record that sales sees as low-activity, because no layer upstream has collapsed them into a single resolved entity. Until that resolution exists at the infrastructure level, the handoff problem cannot be solved by adding more integrations or better dashboards. The data layer itself is fragmented, and every insight built on top of it inherits that fragmentation.
§ 3: The Wrong Fix and the Right One
What does not fix this
The instinct is to upgrade the model, add an explainability layer, or build a better scoring dashboard. Each of these moves addresses the wrong layer. A more capable model reasoning over unresolved, fragmented context produces more confident wrong answers, because the model has no way to know that the four records it is reasoning over represent the same customer. It treats the fragments as distinct signals and synthesizes accordingly. An explainability layer that traces outputs back to fragmented inputs does not fix the problem; it makes the fragmentation visible, which is useful diagnostically but does nothing to resolve it. A better dashboard surfaces the noise with higher production value.
The fix belongs at the layer that prepares context before the model ever sees it. This means infrastructure that resolves entities across systems into a single canonical record, compresses and classifies signals before retrieval so the model receives structure rather than raw fragments, and enforces access permissions at the data layer rather than relying on the model to honor prompt-level instructions. When that layer is absent, the model performs functions it was not designed for: filtering, deduplicating, guessing at identity, and attempting to honor permissions it received as text rather than as structural constraints. Each of those improvisations introduces error. When the layer is present, the model receives a clean, resolved, permissioned context payload and does the one thing it is actually good at: reasoning over it.
The model is a reasoning engine. It is not a data resolution engine, a deduplication engine, or a permission enforcement engine. Asking it to perform those functions is the architectural mistake that produces untrustworthy outputs.
§ 4: What Deterministic Actually Means
The architecture behind the word
Deterministic AI is often used to describe systems that follow explicit rules rather than probabilistic reasoning. That description is not wrong, but it is incomplete, and it locates the determinism in the wrong place.
A working definition: Deterministic AI is an architecture in which identity resolution, signal preparation, and access control produce the same context payload for the same query every time, allowing probabilistic models to reason from deterministic inputs. The model itself remains probabilistic. What changes is the quality and consistency of what it receives. Determinism is a property of the context layer, not the reasoning layer, and that distinction determines whether outputs can be trusted and traced.
At a practical level, deterministic AI requires three architectural properties: deterministic identity resolution, deterministic signal preparation, and deterministic access control. The remainder of this section explains what each one means and why each one must be present for the system to function reliably.
In practice, this means the following. A customer who exists as "Acme Corp" in Salesforce, "acme-cs" in Slack, and "Acme Internal" in Zendesk does not arrive at the model as three competing fragments. A persistent entity graph resolves those aliases to a single canonical identifier before retrieval begins. Every query involving that customer draws from the same resolved record, regardless of which source system it originated in. The model is told the entity. It is not asked to infer it. That single property eliminates an entire class of retrieval errors and makes every downstream output traceable to a specific, verifiable input.
Signal compression works the same way. A thread of 74 messages is reduced to its load-bearing content by a process that applies the same classification logic on every run, separating bug reports from feature requests from sentiment shifts and discarding noise before the context window is assembled. Permission enforcement operates at the retrieval boundary, not as a prompt instruction the model interprets probabilistically. Records the caller cannot see are excluded upstream, not filtered by instruction. The model never encounters unauthorized data, because the architecture ensures it never arrives.
This is a harder set of properties to build than they sound. Entity resolution across enterprise systems requires sustained investment in a global entity map that tracks canonical identifiers, alias resolution, and source-system metadata. Signal compression requires classification infrastructure that has been trained on the specific communication patterns of the organization. Permission enforcement requires that the retrieval layer has access to source-system ACLs and applies them before assembly. None of these are features. They are the components of a deterministic context layer: infrastructure commitments that compound in value with every source added and every workflow built on top of them. Organizations building this are not configuring a tool. They are constructing deterministic context infrastructure that retains value independently of which model runs on top of it.
§ 4.1: How Deterministic AI Differs from Related Concepts
Deterministic AI vs. retrieval-augmented generation. RAG is a retrieval architecture: it determines what information is made available to a model by fetching relevant documents at query time. Deterministic AI is a data preparation architecture: it determines whether the information was assembled correctly before retrieval begins. A RAG system can retrieve well-matched documents that still contain duplicate entities, unresolved identities, and fragments the model must reconcile on its own. Deterministic context infrastructure resolves those problems upstream, so that whatever RAG retrieves is already clean, canonical, and permissioned. The two are not competing approaches. Deterministic context preparation makes RAG retrieval more reliable by improving the quality of what gets retrieved.
Deterministic AI vs. rules engines. Rules engines determine outcomes through predefined conditional logic: if X then Y. Deterministic AI does not determine outcomes. It determines the consistency and integrity of the context a probabilistic model receives. The model still reasons. The rules engine would replace that reasoning with fixed logic. Deterministic context infrastructure keeps the model's reasoning capability intact while removing the fragmentation and ambiguity that degrade it. The distinction matters because rules engines cannot generalize across novel queries. Deterministic context infrastructure can, because it prepares inputs for a model that can.
Deterministic AI vs. agentic AI. Agentic systems use models to plan and execute multi-step tasks autonomously. Determinism is not a property of the agent architecture; it is a property of the context the agent reasons from. An agent operating on fragmented, unresolved context can plan confidently and execute incorrectly, because the information it reasoned from was ambiguous. Deterministic context infrastructure reduces that risk by ensuring the agent's context is resolved, classified, and permissioned before the agent begins planning. The agent's autonomy is preserved. The probability that it acts on incomplete or unauthorized information is structurally reduced.

§ 5: What Changes
What revenue teams can do when context is right
When the context layer resolves entities, compresses signal, and enforces permissions before the model reasons, the outputs that reach revenue teams change in kind, not just in quality. The difference is not speed or volume. It is traceability: every recommendation connects to a specific, verifiable set of inputs rather than a retrieval process no one can inspect.
Account prioritization becomes auditable. The score reflects what specific contacts did, which content they engaged with, and what the engagement pattern looked like relative to other accounts at a comparable stage, because the model received a resolved account record rather than four fragmented versions of it. When a rep challenges the prioritization, the answer is not "the model said so." It is a traceable path from specific signals to a specific conclusion.
Pipeline risk becomes visible earlier for the same reason. Gaps in engagement, delayed follow-up patterns, and missing stakeholder coverage are detectable from structured context because the model is not trying to reconcile conflicting CRM states at inference time. That reconciliation happened upstream, at the data layer, before the query ran. The risk flag carries a traceable explanation because the inputs that produced it are consistent and auditable.
GTM questions get answered without reconciliation overhead. When marketing and sales refer to the same account, they are drawing from the same canonical entity, resolved before either system ran its query. A question about which campaigns are driving pipeline in a specific territory answers from a single resolved data picture rather than a join across systems that produces different results depending on who runs it and when. The reliability of the answer is a function of the context layer, not the model's reasoning capability.
The cumulative effect is reaching the point at which AI recommendations become reliable enough that teams stop applying manual verification by default and begin acting on outputs with confidence. That shift is not a product capability. It is an architectural property built into the layer that prepares context, and it cannot be reached by improving the model or refining the prompt. It requires that the inputs to the model be resolved, consistent, and permissioned before inference begins.
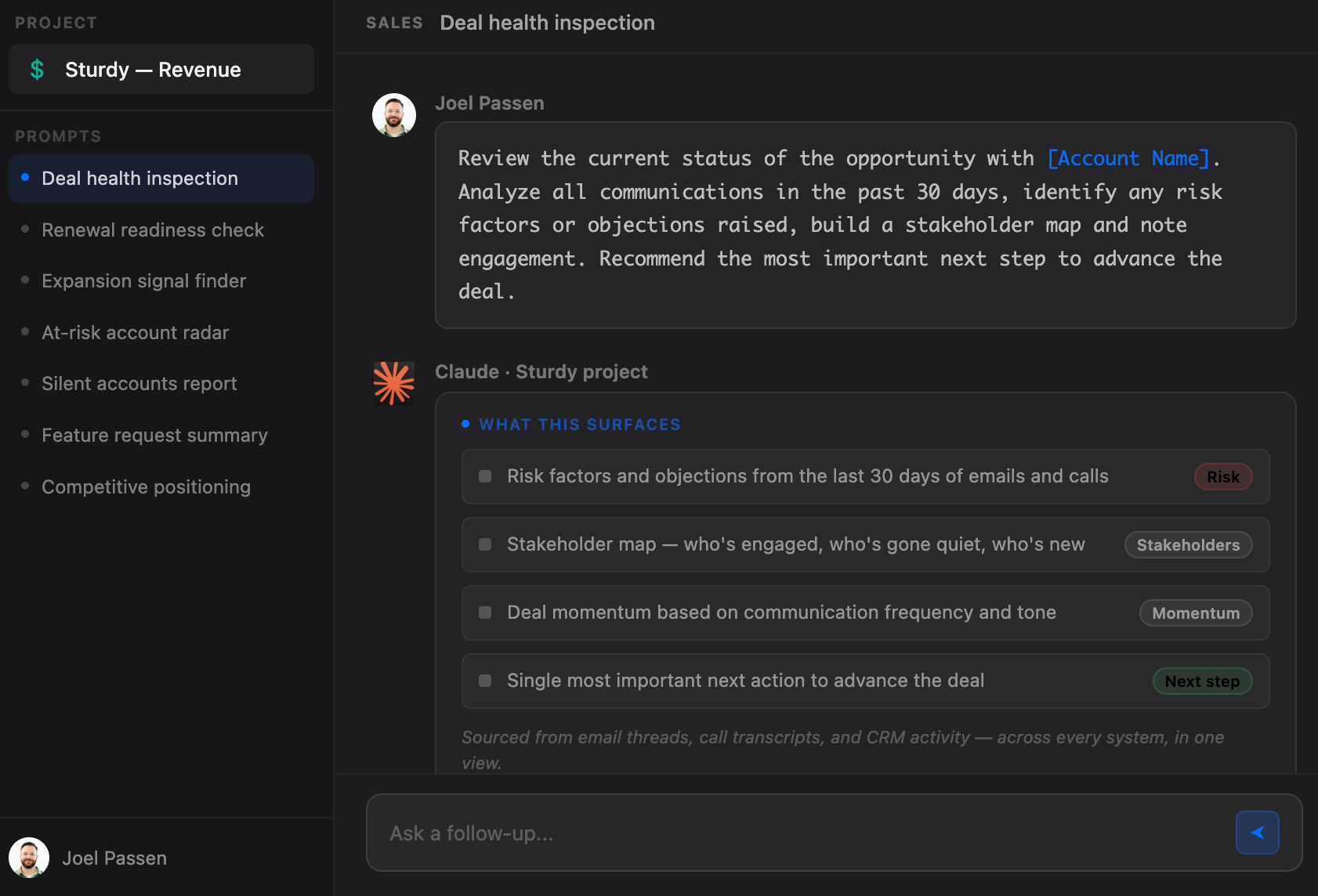
How Sturdy solves this: The context layer, built for revenue data
Sturdy is the infrastructure that sits between your raw data sources and the model. It normalizes entities across Salesforce, Gmail, Slack, Zendesk, Jira, and other systems your revenue team already runs on, collapsing four different records for the same account into a single resolved entity before context assembly begins. Signal is compressed and classified before retrieval: Sturdy separates bug reports from feature requests from sentiment shifts, strips noise, and ensures the highest-signal content arrives first in the context window. Permissions are enforced at the retrieval boundary, not passed as prompt instructions. The model never receives records the caller cannot see, because exclusion happens upstream of inference, not inside it.
The architectural consequence is that the model's job becomes narrower and more reliable. It receives a context payload assembled from resolved, classified, permissioned inputs rather than a window full of fragments it must filter and reconcile before it can reason. That narrowing is what makes outputs traceable. When a recommendation can be challenged, the answer traces back through the context layer to specific signals, specific entities, and specific access decisions, all of which were resolved before the query ran.
The context layer also has a compounding property the model does not. Each source connected, each entity resolved, and each workflow built on top of it increases the coverage and resolution of the intelligence available to every future query. The model running on top of that layer in 2027 will be different from the one running today. The context layer will be the same one, with more accumulated resolution. That asymmetry helps explain why context infrastructure tends to retain value across model generations, while the models themselves continue to change.
.png)

.png)