Welcome to the Sturdy Blog
News and Resources
The latest from Sturdy — product news, insights, and resources.
.png)
The Context Engine
Executive Summary
The Context Engine
The model is not the problem. In every enterprise AI deployment that has hit a production wall in 2026, the failure lives one layer down: in how data is prepared, permissioned, and delivered before the model ever begins reasoning. Model choice has become the wrong question. With Anthropic's Claude surpassing OpenAI in U.S. enterprise adoption (34.4% vs. 32.3%, Ramp AI Index, April 2026), the market has already moved on. The competition has shifted from the Reasoning Engine to the Context Engine.
While nearly every enterprise has deployed frontier models, most are paying a Hallucination Tax they cannot see on their P&L. For an organization with 1,000 knowledge workers, the 4.3 hours per employee per week spent manually verifying AI outputs (Forrester, 2025) equates to approximately $16.8 million in annual salary drain, calculated at a conservative $75 per fully-loaded hour. Multiply that across a global enterprise, and it maps to the $67.4 billion in documented AI hallucination losses recorded in 2024 alone (AllAboutAI, 2025). This is not a failure of the model. It is a failure of architecture.
This paper argues that the next phase of enterprise AI requires a Deterministic Intelligence Layer: infrastructure that normalizes, indexes, and permissions customer data before it reaches the model. Teams replacing token-heavy RAG workflows with deterministic, pre-indexed context are seeing substantial reductions in cost per task while dramatically improving retrieval precision and AI reliability. More importantly, they are crossing the Threshold of Action: the point where AI becomes trustworthy enough to move from surfacing insights to executing workflows.

Section 1
The New Benchmark: Claude's Enterprise Breakout Moment
The AI market just had its crossover moment. As of April 2026, more U.S. businesses pay for Anthropic's Claude than for any other AI model. 34.4% vs. 32.3% for OpenAI, according to the Ramp AI Index, which tracks actual spending across more than 50,000 companies. This isn't a survey about intent. It's purchasing data.
By March 2026, Anthropic was capturing 73% of first-time business AI buyers (Axios, March 2026). A year earlier, one in 25 businesses on Ramp's platform paid for Anthropic. Today, it's nearly one in three.
Enterprise buyers don't switch defaults on a whim. They switch when something is demonstrably working better for the work they actually need done.
The Model Is Not the Problem
Here is the harder truth underneath that adoption story. Despite the crossover, most enterprise AI deployments are not delivering.

Widespread adoption. Widespread underdelivery. Both things are true simultaneously.
The instinct in most organizations is to treat this as a model problem: switch providers, upgrade to the latest version, hire a prompt engineer. None of it moves the needle in any sustained way, because the model is not where the failure lives. Claude is a reasoning engine. A sophisticated one. But a reasoning engine can only reason over what it's given. And in most enterprise deployments, what's given is a mess. Fragments.
The Performance Ceiling
Every technical leader deploying Claude at scale hits the same wall. The demo works. The pilot looks promising. Then it moves toward production, and something breaks. Not catastrophically, but consistently. The AI misattributes an item to the wrong account. It summarizes a customer's history using stale data. It generates an output that sounds authoritative and requires 20 minutes of human verification before it can be trusted.
"Feed a world-class reasoning engine confident, well-structured garbage, and you get the same in return."
This is not a failure of reasoning capability. It is a failure of context architecture. The data required to generate reliable outputs, account history, communications, support activity, call transcripts, and operational metadata typically exists across fragmented systems with inconsistent normalization, disconnected permissions, and no canonical entity resolution layer tying it together.
Context Is the New Infrastructure
The companies pulling ahead in 2026 are not winning because they chose a better model. They are winning because they solved the harder problem underneath it: delivering clean, resolved, permission-aware context before the model ever begins reasoning.
- IT, Data, and Platform Engineering provide the Engine (Claude): a recurring operating expense. World-class reasoning, rented.
- RevOps, Data, and AI Teams provide the Map (the Deterministic Data Layer): a long-term asset. Customer intelligence, owned.
Claude is the current catalyst. The model market will keep moving. New releases, new providers, new pricing. What doesn't move is the underlying problem: fragmented, unresolved, improperly permissioned data. Deterministic context is the durable architecture. The organizations building it now will carry that advantage into every subsequent model generation.
Most organizations already have the engine. What they lack is the map.
Section 2
The Hallucination Tax: Why Fragmented Data Kills AI Performance
If the model isn't the problem, why are so many production-grade AI initiatives hitting a performance ceiling? The answer is the Hallucination Tax.
In 2024, hallucinations cost enterprises an estimated $67.4 billion in global losses (AllAboutAI, 2025). By early 2026, the cost has shifted from outright fabrications to "silent hallucinations": outputs that look structurally perfect but are factually untethered from the current state of the business.
For an organization with 1,000 knowledge workers, the 4.3 hours lost per person per week equates to roughly 223,600 hours of wasted annual productivity, approximately $16.8 million in annual salary drain at a conservative, fully loaded rate. It never appears on the P&L as an AI cost. It shows up as underperformance, missed forecasts, and slower deal cycles.

This forces employees to act as "Human Middleware": the bridge between fragmented systems and the AI that was supposed to make them irrelevant. This tax is the direct result of four specific architectural failure modes.
Failure Mode 1: Retrieval Precision (The Token Tax)
Standard RAG is probabilistic. It retrieves semantically similar fragments, not operational truth. When a sales leader asks, "Why did we lose this seven-figure deal?", the system may surface an old QBR deck instead of the pricing objections in email, the procurement concerns buried in Slack, the legal escalation in Jira, and the product gaps discussed in call transcripts that actually determined the outcome.
Because retrieval is imprecise, teams over-index by stuffing the context window with every possible document to ensure the right one is in there. The result: thousands of reasoning tokens spent filtering noise. A world-class reasoning engine doing the work of a search index.
Failure Mode 2: "Lost in the Middle" (Attention Drift)
Research by Liu et al. (TACL, 2024) demonstrated that accuracy on multi-document reasoning tasks drops by more than 30 percentage points when relevant information is buried in the middle of a long context window. This matters enormously in enterprise environments, where critical signals are scattered across support escalations, pricing discussions, call transcripts, Slack threads, and CRM updates. Simply increasing context size does not solve the problem. In many cases, it amplifies it by forcing the model to attend to more noise.
Failure Mode 3: The Identity Crisis (Entity Disambiguation)
In a fragmented environment, identity is a variable, not a constant. "Jane Doe" in a Zoom transcript needs to resolve to the same Jane Doe in Salesforce, Gmail, Zendesk, Slack, and the CRM activity timeline. Without deterministic entity resolution, the model is forced to infer whether those interactions belong to the same person, account, or buying committee.
Without deterministic entity resolution, the model is forced to reconstruct identity probabilistically. A support escalation tied to one stakeholder, a pricing objection raised in a sales call, and an executive concern discussed over email may be incorrectly assembled into the wrong account narrative entirely.
Failure Mode 4: The Permission Ghost (Unauthorized Surface)
This is the silent killer of enterprise AI programs. Most RAG pipelines lack Source-System Parity. If the AI retrieves a snippet from a private executive email because it was "semantically relevant" to an intern's query, the system has failed regardless of whether anyone noticed.
Incidents like EchoLeak show exactly why retrieval-layer permission enforcement matters. In late 2025, researchers demonstrated a zero-click vulnerability in Microsoft 365 Copilot that could exfiltrate sensitive data from Copilot context without user interaction. No prompt injection required. The retrieval layer was the attack surface.
For most organizations, the permission layer isn't just a technical problem. It is an organizational liability that Legal and Security will eventually force you to solve on a deadline, under pressure, after something has already gone wrong.
The Production Wall
These four failure modes create the Production Wall. A curated demo can appear remarkably accurate. But production environments are not curated. They are noisy, fragmented, and constantly changing, with critical signals distributed across emails, calls, support threads, Slack conversations, and operational systems evolving in real time.
"You cannot solve these four problems by tuning the prompt. You have to solve them by fixing the context."

Section 3
The Deterministic Intelligence Layer
To climb over the Production Wall, enterprise architecture must evolve. The solution is not a larger context window or a more complex prompt. It is a fundamental shift in how data is prepared for the model. Enter the Deterministic Intelligence Layer: infrastructure that sits between your raw data silos and Claude, acting as the architectural antidote to the four failure modes in Section 2.
The Four Pillars
1. Precision Indexing (Ending the Token Tax)
Instead of relying on similarity search alone, the context layer resolves entities, removes duplication, and prioritizes high-signal interactions before retrieval. The model receives structured operational context rather than raw fragments competing for attention.
In Sturdy-observed deployments, replacing raw context with pre-indexed, distilled payloads has reduced token consumption by 80 to 90% on comparable workflows. Results vary by source data density and baseline architecture. You stop paying for Claude to be a search filter.
2. Signal Distillation (Solving "Lost in the Middle")
Semantic Pruning strips HTML headers, Slack noise, legal footers, and the RE: FWD: RE: reply chains that bury every actual decision in 40 lines of quoted text, distilling threads into thematic buckets: Bug Reports, Feature Requests, Sentiment Shifts. The most critical insights land at the beginning of the context window, bypassing the 30-point accuracy drop documented in long-context research.
3. Deterministic Entity Resolution (Fixing the Identity Crisis)
A Global Entity Map resolves disparate naming conventions into a single, immutable Customer ID. Claude is no longer guessing whether two conversations belong to the same account. It is being told they do.
4. Parity-Enforced Permissions (Exorcising the Permission Ghost)
The retrieval layer enforces source-system permissions before context assembly, so unauthorized records are excluded from the payload sent to the model. This is not a prompt-level instruction that can be overridden or confused. It is an architectural enforcement point that sits entirely upstream of the model.
Security becomes a structural property of the architecture, not a probabilistic instruction to the model. Incidents like EchoLeak show why this distinction matters: when permission logic lives inside the prompt, the retrieval layer remains an attack surface. When it lives at the data layer, it doesn't.
Reference Implementation: Sturdy + Claude via MCP
While the merits of this architecture are clear, building it internally results in years of maintenance debt (see Section 5). Sturdy leverages the Model Context Protocol to serve as the Context Engine for Claude, normalizing, indexing, and permission-stamping your customer intelligence layer across Salesforce, Gmail, Slack, and Zendesk before Claude ever queries it.
Claude provides the Reasoning Layer. Sturdy provides the Memory and Context Layer. Together, they move an enterprise from AI that reads your business to AI that acts on it.

Section 4
What It Unlocks: From Reading to Acting
In 2026, summarization is a commodity. The competitive advantage lies in moving from AI that reads your business to AI that acts on it. This transition requires a fundamental shift in how leadership views the AI stack and who owns what.
- IT, Data, and Platform Engineering provide the Engine (Claude): recurring operating expense. World-class reasoning, rented.
- RevOps, Data, and AI Teams provide the Map (the Deterministic Data Layer): a long-term asset. Customer intelligence, owned, not rented.
When the engine has a perfect map, the Acceleration Gap closes.
RevOps: The Revenue Architect
For the RevOps leader, a deterministic layer turns fragmented operational data into active revenue signals. Instead of building static dashboards that explain why a quarter was missed, RevOps can monitor the commercial signals that actually move deals: pricing hesitation in email, procurement delays, legal friction, competitive mentions, executive disengagement, stalled next steps, and tone changes across active opportunities.
A deterministic context layer resolves those signals to the right person, account, opportunity, and timeline before AI ever reasons over them. That is what turns scattered communication into reliable revenue action.
RevOps stops being a report generator. It becomes the operating system for revenue execution: designing the logic that turns verified commercial signals into coordinated GTM action.
Sales: Instant Account Intelligence
The average sales rep spends roughly 20% of their week on pre-call research. With a deterministic layer, the account briefing is no longer a probabilistic summary. It is a verified snapshot: "The customer's last three support tickets were resolved, but they haven't yet implemented the API update discussed in the March QBR."
Product: The Automated Feedback Loop
Product managers are often the most data-rich but insight-poor employees in the company. A deterministic layer moves PMs from reading feedback to querying insights. Claude analyzes 60 days of feedback across Slack and Zendesk and, with a single prompt, generates a high-fidelity Jira ticket including exact customer quotes, impacted account IDs, and revenue at risk.
Customer Success: Proactive Triage
In CS, latency is the enemy. A deterministic layer allows Claude to perform live triage. When a customer sends a frustrated email, the AI checks contract terms and recent product usage logs before the CSM has finished reading the subject line. It presents a Context-Aware Response ready to send, grounded in verified account data.
"The model you license today is rent. The customer intelligence layer you build is equity. One gets replaced. The other compounds."
Every account signal normalized, every entity resolved, every permission enforced. That accumulates. The organizations building this layer now are building institutional memory that makes every model they run on top of it better.

Section 5
The Build vs. Buy Reality
The instinct for most sophisticated IT and data teams is to build. It is a legitimate impulse. The stack looks deceptively simple: a few API connectors, a vector database, and some chunking logic. In the demo phase, an internal build often feels like the most cost-effective path.

The Four Hidden Engineering Hurdles
1. The Normalization Treadmill
Building a connector to Salesforce is straightforward. Maintaining the logic layer that resolves entity names across Salesforce, Slack, and Zendesk as those systems' schemas evolve is a full-time engineering job. This is Semantic Drift: hundreds of developer hours consumed by maintenance rather than innovation.
2. The Permission Mapping Paradox
Mapping row-level permissions from source systems into an AI context window is one of the most complex security challenges in modern software. Most internal builds rely on prompt-level security, which fails under the weight of incidents like EchoLeak. This isn't a technical trade-off. It is an organizational liability waiting to be forced into crisis.
3. The Latency Wall
A custom RAG pipeline often takes 5 to 10 seconds to fetch and clean data. In Sturdy-observed deployments, pre-indexed deterministic retrieval consistently operates under 1 second on production data volumes, but reaching that benchmark requires specialized search infrastructure expertise that is rarely the core competency of a generalist data team building from scratch.
4. The Token Optimization Tax
Without signal distillation, internal builds routinely pass 3x to 5x more tokens than necessary. Teams save on build costs only to spend twice as much on model API costs.
Where Does Your Engineering Dollar Go?
The strategic question isn't "Can we build this?" It's "Should we own the maintenance of this?"

Competitive advantage does not live in the plumbing. No customer chooses a vendor because their AI has a better Python script for cleaning Slack data.
By offloading the Normalization Treadmill to Sturdy, organizations are promoting their engineering teams from Data Cleaners to AI Product Owners, moving their best people away from the maintenance treadmill and toward the high-value work of building AI that drives revenue.
Buy the plumbing. Build the logic. The teams doing this are shipping revenue-generating AI workflows, while their competitors are still debugging entity-resolution scripts.
Section 6
What to Do Now: The 2026 Roadmap
The Acceleration Gap is not a permanent state. It is a choice of architecture. The move is not to wait for a smarter model. The move is to fix the context. Here are four moves for leadership to take in the next 90 days.
Move 1: Audit Your Retrieval Precision, Not Your Prompts
Most teams spend the majority of their time prompt-tuning errors caused by bad data retrieval. The action: Run a Ground Truth test. Take ten complex customer queries and manually check the data fragments Claude is being fed. If more than 20% of that data is noisy, stale, or misattributed, no prompt engineering will save the deployment. You have a plumbing problem, not a reasoning problem.
Move 2: Isolate a Multi-Source Workflow
The highest ROI for a deterministic layer is found where data is most fragmented. The action: Pick a high-value, closed-loop use case where data lives in at least three systems. For example: the path from customer feedback in Slack and Zendesk to an engineering action in Jira. Solve the context problem here, and you've built a blueprint for the rest of the organization.
Move 3: Enforce Permissions at the Data Layer
Stop treating security as a probabilistic instruction. The action: Move permission enforcement out of the system prompt and into the retrieval infrastructure. Ensure the retrieval layer enforces source-system permissions before context assembly, so unauthorized records never reach the model. The Permission Ghost is exorcised structurally, not instructionally, and the organizational liability is removed before Legal ever has to get involved.
Move 4: Define Where AI Earns the Right to Act
The distance between AI that summarizes and AI that executes is a trust gap, not a technology gap. The action: Build human-in-the-loop approval gates for high-stakes actions. Drafting a renewal contract. Creating a Jira ticket. Sending a support response. Use your deterministic layer to provide the required Confidence Equity. The threshold to target is a sub-5% error rate on AI-generated drafts. That is the point at which approval gates can be safely reduced, and workflows become self-sustaining.
Traditional probabilistic RAG architectures struggle to reach this threshold consistently at enterprise scale. Because probabilistic retrieval introduces entity errors, stale data, and permission noise, error rates on complex multi-source tasks typically stabilize in the 15 to 30% range regardless of prompt quality, even with hybrid retrieval and reranking layers added on top.
A deterministic layer that resolves entities before inference, distills the signal before retrieval, and enforces permissions before the model ever sees the data is the only architecture that makes sub-5% structurally achievable, rather than an occasional lucky outcome.
In Sturdy-observed deployments, teams that reach this threshold have consistently moved to reduced-oversight approval workflows within a quarter. Results depend on workflow complexity and baseline data quality. Reaching the sub-5% Trust Threshold is the definitive signal that an organization has graduated from "AI Experiments" to a Context Engine architecture capable of autonomous action. That is the architectural line between AI that assists and AI that acts.

Conclusion
The Architectural Advantage
Frontier models will continue to improve and commoditize. The durable advantage is no longer the model itself. It is the architecture surrounding it.
The long-term value does not live in another standalone AI interface. Interfaces change too quickly. The durable layer is the operational context infrastructure beneath them.
Organizations that solve deterministic context assembly, entity resolution, permission-aware retrieval, and operational state assembly gain a compounding advantage independent of whichever model, interface, or orchestration layer dominates next year.
Organizations that solve context architecture today are building infrastructure that compounds across model generations. As interfaces evolve and models improve, the operational context layer beneath them becomes increasingly valuable.
"The era of the Context Engine is here. Is your architecture ready for it?"

Executive Summary
The Context Engine
The model is not the problem. In every enterprise AI deployment that has hit a production wall in 2026, the failure lives one layer down: in how data is prepared, permissioned, and delivered before the model ever begins reasoning. Model choice has become the wrong question. With Anthropic's Claude surpassing OpenAI in U.S. enterprise adoption (34.4% vs. 32.3%, Ramp AI Index, April 2026), the market has already moved on. The competition has shifted from the Reasoning Engine to the Context Engine.
While nearly every enterprise has deployed frontier models, most are paying a Hallucination Tax they cannot see on their P&L. For an organization with 1,000 knowledge workers, the 4.3 hours per employee per week spent manually verifying AI outputs (Forrester, 2025) equates to approximately $16.8 million in annual salary drain, calculated at a conservative $75 per fully-loaded hour. Multiply that across a global enterprise, and it maps to the $67.4 billion in documented AI hallucination losses recorded in 2024 alone (AllAboutAI, 2025). This is not a failure of the model. It is a failure of architecture.
This paper argues that the next phase of enterprise AI requires a Deterministic Intelligence Layer: infrastructure that normalizes, indexes, and permissions customer data before it reaches the model. Teams replacing token-heavy RAG workflows with deterministic, pre-indexed context are seeing substantial reductions in cost per task while dramatically improving retrieval precision and AI reliability. More importantly, they are crossing the Threshold of Action: the point where AI becomes trustworthy enough to move from surfacing insights to executing workflows.
Section 1
The New Benchmark: Claude's Enterprise Breakout Moment
The AI market just had its crossover moment. As of April 2026, more U.S. businesses pay for Anthropic's Claude than for any other AI model. 34.4% vs. 32.3% for OpenAI, according to the Ramp AI Index, which tracks actual spending across more than 50,000 companies. This isn't a survey about intent. It's purchasing data.
By March 2026, Anthropic was capturing 73% of first-time business AI buyers (Axios, March 2026). A year earlier, one in 25 businesses on Ramp's platform paid for Anthropic. Today, it's nearly one in three.
Enterprise buyers don't switch defaults on a whim. They switch when something is demonstrably working better for the work they actually need done.
The Model Is Not the Problem
Here is the harder truth underneath that adoption story. Despite the crossover, most enterprise AI deployments are not delivering.
Widespread adoption. Widespread underdelivery. Both things are true simultaneously.
The instinct in most organizations is to treat this as a model problem: switch providers, upgrade to the latest version, hire a prompt engineer. None of it moves the needle in any sustained way, because the model is not where the failure lives. Claude is a reasoning engine. A sophisticated one. But a reasoning engine can only reason over what it's given. And in most enterprise deployments, what's given is a mess. Fragments.
The Performance Ceiling
Every technical leader deploying Claude at scale hits the same wall. The demo works. The pilot looks promising. Then it moves toward production, and something breaks. Not catastrophically, but consistently. The AI misattributes an item to the wrong account. It summarizes a customer's history using stale data. It generates an output that sounds authoritative and requires 20 minutes of human verification before it can be trusted.
"Feed a world-class reasoning engine confident, well-structured garbage, and you get the same in return."
This is not a failure of reasoning capability. It is a failure of context architecture. The data required to generate reliable outputs, account history, communications, support activity, call transcripts, and operational metadata typically exists across fragmented systems with inconsistent normalization, disconnected permissions, and no canonical entity resolution layer tying it together.
Context Is the New Infrastructure
The companies pulling ahead in 2026 are not winning because they chose a better model. They are winning because they solved the harder problem underneath it: delivering clean, resolved, permission-aware context before the model ever begins reasoning.
- IT, Data, and Platform Engineering provide the Engine (Claude): a recurring operating expense. World-class reasoning, rented.
- RevOps, Data, and AI Teams provide the Map (the Deterministic Data Layer): a long-term asset. Customer intelligence, owned.
Claude is the current catalyst. The model market will keep moving. New releases, new providers, new pricing. What doesn't move is the underlying problem: fragmented, unresolved, improperly permissioned data. Deterministic context is the durable architecture. The organizations building it now will carry that advantage into every subsequent model generation.
Most organizations already have the engine. What they lack is the map.
Section 2
The Hallucination Tax: Why Fragmented Data Kills AI Performance
If the model isn't the problem, why are so many production-grade AI initiatives hitting a performance ceiling? The answer is the Hallucination Tax.
In 2024, hallucinations cost enterprises an estimated $67.4 billion in global losses (AllAboutAI, 2025). By early 2026, the cost has shifted from outright fabrications to "silent hallucinations": outputs that look structurally perfect but are factually untethered from the current state of the business.
For an organization with 1,000 knowledge workers, the 4.3 hours lost per person per week equates to roughly 223,600 hours of wasted annual productivity, approximately $16.8 million in annual salary drain at a conservative, fully loaded rate. It never appears on the P&L as an AI cost. It shows up as underperformance, missed forecasts, and slower deal cycles.
This forces employees to act as "Human Middleware": the bridge between fragmented systems and the AI that was supposed to make them irrelevant. This tax is the direct result of four specific architectural failure modes.
Failure Mode 1: Retrieval Precision (The Token Tax)
Standard RAG is probabilistic. It retrieves semantically similar fragments, not operational truth. When a sales leader asks, "Why did we lose this seven-figure deal?", the system may surface an old QBR deck instead of the pricing objections in email, the procurement concerns buried in Slack, the legal escalation in Jira, and the product gaps discussed in call transcripts that actually determined the outcome.
Because retrieval is imprecise, teams over-index by stuffing the context window with every possible document to ensure the right one is in there. The result: thousands of reasoning tokens spent filtering noise. A world-class reasoning engine doing the work of a search index.
Failure Mode 2: "Lost in the Middle" (Attention Drift)
Research by Liu et al. (TACL, 2024) demonstrated that accuracy on multi-document reasoning tasks drops by more than 30 percentage points when relevant information is buried in the middle of a long context window. This matters enormously in enterprise environments, where critical signals are scattered across support escalations, pricing discussions, call transcripts, Slack threads, and CRM updates. Simply increasing context size does not solve the problem. In many cases, it amplifies it by forcing the model to attend to more noise.
Failure Mode 3: The Identity Crisis (Entity Disambiguation)
In a fragmented environment, identity is a variable, not a constant. "Jane Doe" in a Zoom transcript needs to resolve to the same Jane Doe in Salesforce, Gmail, Zendesk, Slack, and the CRM activity timeline. Without deterministic entity resolution, the model is forced to infer whether those interactions belong to the same person, account, or buying committee.
Without deterministic entity resolution, the model is forced to reconstruct identity probabilistically. A support escalation tied to one stakeholder, a pricing objection raised in a sales call, and an executive concern discussed over email may be incorrectly assembled into the wrong account narrative entirely.
Failure Mode 4: The Permission Ghost (Unauthorized Surface)
This is the silent killer of enterprise AI programs. Most RAG pipelines lack Source-System Parity. If the AI retrieves a snippet from a private executive email because it was "semantically relevant" to an intern's query, the system has failed regardless of whether anyone noticed.
Incidents like EchoLeak show exactly why retrieval-layer permission enforcement matters. In late 2025, researchers demonstrated a zero-click vulnerability in Microsoft 365 Copilot that could exfiltrate sensitive data from Copilot context without user interaction. No prompt injection required. The retrieval layer was the attack surface.
For most organizations, the permission layer isn't just a technical problem. It is an organizational liability that Legal and Security will eventually force you to solve on a deadline, under pressure, after something has already gone wrong.
The Production Wall
These four failure modes create the Production Wall. A curated demo can appear remarkably accurate. But production environments are not curated. They are noisy, fragmented, and constantly changing, with critical signals distributed across emails, calls, support threads, Slack conversations, and operational systems evolving in real time.
"You cannot solve these four problems by tuning the prompt. You have to solve them by fixing the context."
Section 3
The Deterministic Intelligence Layer
To climb over the Production Wall, enterprise architecture must evolve. The solution is not a larger context window or a more complex prompt. It is a fundamental shift in how data is prepared for the model. Enter the Deterministic Intelligence Layer: infrastructure that sits between your raw data silos and Claude, acting as the architectural antidote to the four failure modes in Section 2.
The Four Pillars
1. Precision Indexing (Ending the Token Tax)
Instead of relying on similarity search alone, the context layer resolves entities, removes duplication, and prioritizes high-signal interactions before retrieval. The model receives structured operational context rather than raw fragments competing for attention.
In Sturdy-observed deployments, replacing raw context with pre-indexed, distilled payloads has reduced token consumption by 80 to 90% on comparable workflows. Results vary by source data density and baseline architecture. You stop paying for Claude to be a search filter.
2. Signal Distillation (Solving "Lost in the Middle")
Semantic Pruning strips HTML headers, Slack noise, legal footers, and the RE: FWD: RE: reply chains that bury every actual decision in 40 lines of quoted text, distilling threads into thematic buckets: Bug Reports, Feature Requests, Sentiment Shifts. The most critical insights land at the beginning of the context window, bypassing the 30-point accuracy drop documented in long-context research.
3. Deterministic Entity Resolution (Fixing the Identity Crisis)
A Global Entity Map resolves disparate naming conventions into a single, immutable Customer ID. Claude is no longer guessing whether two conversations belong to the same account. It is being told they do.
4. Parity-Enforced Permissions (Exorcising the Permission Ghost)
The retrieval layer enforces source-system permissions before context assembly, so unauthorized records are excluded from the payload sent to the model. This is not a prompt-level instruction that can be overridden or confused. It is an architectural enforcement point that sits entirely upstream of the model.
Security becomes a structural property of the architecture, not a probabilistic instruction to the model. Incidents like EchoLeak show why this distinction matters: when permission logic lives inside the prompt, the retrieval layer remains an attack surface. When it lives at the data layer, it doesn't.
Reference Implementation: Sturdy + Claude via MCP
While the merits of this architecture are clear, building it internally results in years of maintenance debt (see Section 5). Sturdy leverages the Model Context Protocol to serve as the Context Engine for Claude, normalizing, indexing, and permission-stamping your customer intelligence layer across Salesforce, Gmail, Slack, and Zendesk before Claude ever queries it.
Claude provides the Reasoning Layer. Sturdy provides the Memory and Context Layer. Together, they move an enterprise from AI that reads your business to AI that acts on it.
Section 4
What It Unlocks: From Reading to Acting
In 2026, summarization is a commodity. The competitive advantage lies in moving from AI that reads your business to AI that acts on it. This transition requires a fundamental shift in how leadership views the AI stack and who owns what.
- IT, Data, and Platform Engineering provide the Engine (Claude): recurring operating expense. World-class reasoning, rented.
- RevOps, Data, and AI Teams provide the Map (the Deterministic Data Layer): a long-term asset. Customer intelligence, owned, not rented.
When the engine has a perfect map, the Acceleration Gap closes.
RevOps: The Revenue Architect
For the RevOps leader, a deterministic layer turns fragmented operational data into active revenue signals. Instead of building static dashboards that explain why a quarter was missed, RevOps can monitor the commercial signals that actually move deals: pricing hesitation in email, procurement delays, legal friction, competitive mentions, executive disengagement, stalled next steps, and tone changes across active opportunities.
A deterministic context layer resolves those signals to the right person, account, opportunity, and timeline before AI ever reasons over them. That is what turns scattered communication into reliable revenue action.
RevOps stops being a report generator. It becomes the operating system for revenue execution: designing the logic that turns verified commercial signals into coordinated GTM action.
Sales: Instant Account Intelligence
The average sales rep spends roughly 20% of their week on pre-call research. With a deterministic layer, the account briefing is no longer a probabilistic summary. It is a verified snapshot: "The customer's last three support tickets were resolved, but they haven't yet implemented the API update discussed in the March QBR."
Product: The Automated Feedback Loop
Product managers are often the most data-rich but insight-poor employees in the company. A deterministic layer moves PMs from reading feedback to querying insights. Claude analyzes 60 days of feedback across Slack and Zendesk and, with a single prompt, generates a high-fidelity Jira ticket including exact customer quotes, impacted account IDs, and revenue at risk.
Customer Success: Proactive Triage
In CS, latency is the enemy. A deterministic layer allows Claude to perform live triage. When a customer sends a frustrated email, the AI checks contract terms and recent product usage logs before the CSM has finished reading the subject line. It presents a Context-Aware Response ready to send, grounded in verified account data.
"The model you license today is rent. The customer intelligence layer you build is equity. One gets replaced. The other compounds."
Every account signal normalized, every entity resolved, every permission enforced. That accumulates. The organizations building this layer now are building institutional memory that makes every model they run on top of it better.
Section 5
The Build vs. Buy Reality
The instinct for most sophisticated IT and data teams is to build. It is a legitimate impulse. The stack looks deceptively simple: a few API connectors, a vector database, and some chunking logic. In the demo phase, an internal build often feels like the most cost-effective path.
The Four Hidden Engineering Hurdles
1. The Normalization Treadmill
Building a connector to Salesforce is straightforward. Maintaining the logic layer that resolves entity names across Salesforce, Slack, and Zendesk as those systems' schemas evolve is a full-time engineering job. This is Semantic Drift: hundreds of developer hours consumed by maintenance rather than innovation.
2. The Permission Mapping Paradox
Mapping row-level permissions from source systems into an AI context window is one of the most complex security challenges in modern software. Most internal builds rely on prompt-level security, which fails under the weight of incidents like EchoLeak. This isn't a technical trade-off. It is an organizational liability waiting to be forced into crisis.
3. The Latency Wall
A custom RAG pipeline often takes 5 to 10 seconds to fetch and clean data. In Sturdy-observed deployments, pre-indexed deterministic retrieval consistently operates under 1 second on production data volumes, but reaching that benchmark requires specialized search infrastructure expertise that is rarely the core competency of a generalist data team building from scratch.
4. The Token Optimization Tax
Without signal distillation, internal builds routinely pass 3x to 5x more tokens than necessary. Teams save on build costs only to spend twice as much on model API costs.
Where Does Your Engineering Dollar Go?
The strategic question isn't "Can we build this?" It's "Should we own the maintenance of this?"
Competitive advantage does not live in the plumbing. No customer chooses a vendor because their AI has a better Python script for cleaning Slack data.
By offloading the Normalization Treadmill to Sturdy, organizations are promoting their engineering teams from Data Cleaners to AI Product Owners, moving their best people away from the maintenance treadmill and toward the high-value work of building AI that drives revenue.
Buy the plumbing. Build the logic. The teams doing this are shipping revenue-generating AI workflows, while their competitors are still debugging entity-resolution scripts.
Section 6
What to Do Now: The 2026 Roadmap
The Acceleration Gap is not a permanent state. It is a choice of architecture. The move is not to wait for a smarter model. The move is to fix the context. Here are four moves for leadership to take in the next 90 days.
Move 1: Audit Your Retrieval Precision, Not Your Prompts
Most teams spend the majority of their time prompt-tuning errors caused by bad data retrieval. The action: Run a Ground Truth test. Take ten complex customer queries and manually check the data fragments Claude is being fed. If more than 20% of that data is noisy, stale, or misattributed, no prompt engineering will save the deployment. You have a plumbing problem, not a reasoning problem.
Move 2: Isolate a Multi-Source Workflow
The highest ROI for a deterministic layer is found where data is most fragmented. The action: Pick a high-value, closed-loop use case where data lives in at least three systems. For example: the path from customer feedback in Slack and Zendesk to an engineering action in Jira. Solve the context problem here, and you've built a blueprint for the rest of the organization.
Move 3: Enforce Permissions at the Data Layer
Stop treating security as a probabilistic instruction. The action: Move permission enforcement out of the system prompt and into the retrieval infrastructure. Ensure the retrieval layer enforces source-system permissions before context assembly, so unauthorized records never reach the model. The Permission Ghost is exorcised structurally, not instructionally, and the organizational liability is removed before Legal ever has to get involved.
Move 4: Define Where AI Earns the Right to Act
The distance between AI that summarizes and AI that executes is a trust gap, not a technology gap. The action: Build human-in-the-loop approval gates for high-stakes actions. Drafting a renewal contract. Creating a Jira ticket. Sending a support response. Use your deterministic layer to provide the required Confidence Equity. The threshold to target is a sub-5% error rate on AI-generated drafts. That is the point at which approval gates can be safely reduced, and workflows become self-sustaining.
Traditional probabilistic RAG architectures struggle to reach this threshold consistently at enterprise scale. Because probabilistic retrieval introduces entity errors, stale data, and permission noise, error rates on complex multi-source tasks typically stabilize in the 15 to 30% range regardless of prompt quality, even with hybrid retrieval and reranking layers added on top.
A deterministic layer that resolves entities before inference, distills the signal before retrieval, and enforces permissions before the model ever sees the data is the only architecture that makes sub-5% structurally achievable, rather than an occasional lucky outcome.
In Sturdy-observed deployments, teams that reach this threshold have consistently moved to reduced-oversight approval workflows within a quarter. Results depend on workflow complexity and baseline data quality. Reaching the sub-5% Trust Threshold is the definitive signal that an organization has graduated from "AI Experiments" to a Context Engine architecture capable of autonomous action. That is the architectural line between AI that assists and AI that acts.
Conclusion
The Architectural Advantage
Frontier models will continue to improve and commoditize. The durable advantage is no longer the model itself. It is the architecture surrounding it.
The long-term value does not live in another standalone AI interface. Interfaces change too quickly. The durable layer is the operational context infrastructure beneath them.
Organizations that solve deterministic context assembly, entity resolution, permission-aware retrieval, and operational state assembly gain a compounding advantage independent of whichever model, interface, or orchestration layer dominates next year.
Organizations that solve context architecture today are building infrastructure that compounds across model generations. As interfaces evolve and models improve, the operational context layer beneath them becomes increasingly valuable.
"The era of the Context Engine is here. Is your architecture ready for it?"
Our articles

What Deterministic AI Actually Means for Enterprise Revenue Teams
§ 1: The Setup
More signal, less action
Revenue teams have never had access to more AI-generated output. Intent signals, engagement scores, pipeline risk flags, account summaries generated from CRM data, recommended next actions populated into dashboards before the morning standup. The tools are proliferating. The outputs are multiplying. And yet, in most enterprise GTM organizations, the conversion from AI insight to actual decision is stagnating or declining.
The default diagnosis is a model problem or a product problem. The model is not accurate enough. The tool is not integrated deeply enough. The outputs are not surfaced in the right workflow. These are real friction points, but they are not the root cause. Fixing them at the application layer produces better-looking noise, not better decisions.
The actual problem is architectural, and it sits one layer below the model. Enterprise revenue data arrives fragmented: the same account exists as four different entities across Salesforce, Gong, HubSpot, and Zendesk. Engagement signals carry different timestamps, different field schemas, different definitions of what counts as a meaningful interaction. Permissions are enforced inconsistently, or not at all, before context reaches the model. When the model reasons over this, it is not reasoning over your business. It is reasoning over a probabilistic reconstruction of your business, assembled at runtime from inputs that contradict each other.
The result is outputs that teams cannot validate, cannot trace, and eventually stop trusting. The insight-to-action gap is not a UX problem. It is a data preparation problem that most organizations have not yet named correctly.
None of these data problems are new. Revenue systems have been fragmented for decades. What changed is that analysts used to perform the reconciliation manually. AI systems consume context directly. Every unresolved identity, duplicated record, and permission inconsistency that once slowed down an analyst now becomes part of the model's reasoning process. The rise of AI did not create the context problem. It exposed it.
Core argument: When the context layer is broken, no model is accurate enough. When it is built correctly, model selection becomes a secondary decision.
§ 2: Failure Patterns
Three failure patterns revenue teams actually recognize
The breakdown follows predictable patterns. Understanding the mechanism behind each one clarifies why application-layer fixes keep failing to address them.
Too many signals, no resolution. Modern GTM stacks produce a high volume of engagement data: web activity, intent signals, email opens, CRM updates, product usage events, support tickets. The problem is not the volume. The problem is that the same customer arrives as multiple disconnected records, each carrying a fragment of a complete picture. When retrieval pulls context for a model to reason over, it assembles a window full of candidates that may represent the same entity under four different identifiers. The model filters and weighs this noise because nothing upstream resolved it. That filtering costs tokens, introduces error, and produces outputs with confidence levels that cannot be verified against a ground truth. Teams receive a prioritization recommendation that reflects the quality of the retrieval, not the reality of the account.
Scores that cannot be traced. A high-priority account flag, a churn risk score, a pipeline confidence number. These outputs only change behavior if the team receiving them can validate the reasoning. When the underlying signals are fragmented, duplicated, or sourced from systems with inconsistent definitions, the model's output is not traceable to a specific set of inputs. The recommendation is real, but the path from data to conclusion runs through a retrieval process no one can inspect. Teams hesitate, override, or ignore, not because the model is wrong, but because they have no way to confirm it is right. Explainability is a function of what the model received, not just how it reasoned.
Insights that do not survive the handoff. Revenue organizations run across systems. Marketing works in attribution platforms. Sales lives in CRM. RevOps reconciles both. An AI output generated in one system rarely arrives intact in another, because the entity it references does not have a consistent identity across those systems. The account that marketing flagged as highly engaged is not the same record that sales sees as low-activity, because no layer upstream has collapsed them into a single resolved entity. Until that resolution exists at the infrastructure level, the handoff problem cannot be solved by adding more integrations or better dashboards. The data layer itself is fragmented, and every insight built on top of it inherits that fragmentation.
§ 3: The Wrong Fix and the Right One
What does not fix this
The instinct is to upgrade the model, add an explainability layer, or build a better scoring dashboard. Each of these moves addresses the wrong layer. A more capable model reasoning over unresolved, fragmented context produces more confident wrong answers, because the model has no way to know that the four records it is reasoning over represent the same customer. It treats the fragments as distinct signals and synthesizes accordingly. An explainability layer that traces outputs back to fragmented inputs does not fix the problem; it makes the fragmentation visible, which is useful diagnostically but does nothing to resolve it. A better dashboard surfaces the noise with higher production value.
The fix belongs at the layer that prepares context before the model ever sees it. This means infrastructure that resolves entities across systems into a single canonical record, compresses and classifies signals before retrieval so the model receives structure rather than raw fragments, and enforces access permissions at the data layer rather than relying on the model to honor prompt-level instructions. When that layer is absent, the model performs functions it was not designed for: filtering, deduplicating, guessing at identity, and attempting to honor permissions it received as text rather than as structural constraints. Each of those improvisations introduces error. When the layer is present, the model receives a clean, resolved, permissioned context payload and does the one thing it is actually good at: reasoning over it.
The model is a reasoning engine. It is not a data resolution engine, a deduplication engine, or a permission enforcement engine. Asking it to perform those functions is the architectural mistake that produces untrustworthy outputs.
§ 4: What Deterministic Actually Means
The architecture behind the word
Deterministic AI is often used to describe systems that follow explicit rules rather than probabilistic reasoning. That description is not wrong, but it is incomplete, and it locates the determinism in the wrong place.
A working definition: Deterministic AI is an architecture in which identity resolution, signal preparation, and access control produce the same context payload for the same query every time, allowing probabilistic models to reason from deterministic inputs. The model itself remains probabilistic. What changes is the quality and consistency of what it receives. Determinism is a property of the context layer, not the reasoning layer, and that distinction determines whether outputs can be trusted and traced.
At a practical level, deterministic AI requires three architectural properties: deterministic identity resolution, deterministic signal preparation, and deterministic access control. The remainder of this section explains what each one means and why each one must be present for the system to function reliably.
In practice, this means the following. A customer who exists as "Acme Corp" in Salesforce, "acme-cs" in Slack, and "Acme Internal" in Zendesk does not arrive at the model as three competing fragments. A persistent entity graph resolves those aliases to a single canonical identifier before retrieval begins. Every query involving that customer draws from the same resolved record, regardless of which source system it originated in. The model is told the entity. It is not asked to infer it. That single property eliminates an entire class of retrieval errors and makes every downstream output traceable to a specific, verifiable input.
Signal compression works the same way. A thread of 74 messages is reduced to its load-bearing content by a process that applies the same classification logic on every run, separating bug reports from feature requests from sentiment shifts and discarding noise before the context window is assembled. Permission enforcement operates at the retrieval boundary, not as a prompt instruction the model interprets probabilistically. Records the caller cannot see are excluded upstream, not filtered by instruction. The model never encounters unauthorized data, because the architecture ensures it never arrives.
This is a harder set of properties to build than they sound. Entity resolution across enterprise systems requires sustained investment in a global entity map that tracks canonical identifiers, alias resolution, and source-system metadata. Signal compression requires classification infrastructure that has been trained on the specific communication patterns of the organization. Permission enforcement requires that the retrieval layer has access to source-system ACLs and applies them before assembly. None of these are features. They are the components of a deterministic context layer: infrastructure commitments that compound in value with every source added and every workflow built on top of them. Organizations building this are not configuring a tool. They are constructing deterministic context infrastructure that retains value independently of which model runs on top of it.
§ 4.1: How Deterministic AI Differs from Related Concepts
Deterministic AI vs. retrieval-augmented generation. RAG is a retrieval architecture: it determines what information is made available to a model by fetching relevant documents at query time. Deterministic AI is a data preparation architecture: it determines whether the information was assembled correctly before retrieval begins. A RAG system can retrieve well-matched documents that still contain duplicate entities, unresolved identities, and fragments the model must reconcile on its own. Deterministic context infrastructure resolves those problems upstream, so that whatever RAG retrieves is already clean, canonical, and permissioned. The two are not competing approaches. Deterministic context preparation makes RAG retrieval more reliable by improving the quality of what gets retrieved.
Deterministic AI vs. rules engines. Rules engines determine outcomes through predefined conditional logic: if X then Y. Deterministic AI does not determine outcomes. It determines the consistency and integrity of the context a probabilistic model receives. The model still reasons. The rules engine would replace that reasoning with fixed logic. Deterministic context infrastructure keeps the model's reasoning capability intact while removing the fragmentation and ambiguity that degrade it. The distinction matters because rules engines cannot generalize across novel queries. Deterministic context infrastructure can, because it prepares inputs for a model that can.
Deterministic AI vs. agentic AI. Agentic systems use models to plan and execute multi-step tasks autonomously. Determinism is not a property of the agent architecture; it is a property of the context the agent reasons from. An agent operating on fragmented, unresolved context can plan confidently and execute incorrectly, because the information it reasoned from was ambiguous. Deterministic context infrastructure reduces that risk by ensuring the agent's context is resolved, classified, and permissioned before the agent begins planning. The agent's autonomy is preserved. The probability that it acts on incomplete or unauthorized information is structurally reduced.

§ 5: What Changes
What revenue teams can do when context is right
When the context layer resolves entities, compresses signal, and enforces permissions before the model reasons, the outputs that reach revenue teams change in kind, not just in quality. The difference is not speed or volume. It is traceability: every recommendation connects to a specific, verifiable set of inputs rather than a retrieval process no one can inspect.
Account prioritization becomes auditable. The score reflects what specific contacts did, which content they engaged with, and what the engagement pattern looked like relative to other accounts at a comparable stage, because the model received a resolved account record rather than four fragmented versions of it. When a rep challenges the prioritization, the answer is not "the model said so." It is a traceable path from specific signals to a specific conclusion.
Pipeline risk becomes visible earlier for the same reason. Gaps in engagement, delayed follow-up patterns, and missing stakeholder coverage are detectable from structured context because the model is not trying to reconcile conflicting CRM states at inference time. That reconciliation happened upstream, at the data layer, before the query ran. The risk flag carries a traceable explanation because the inputs that produced it are consistent and auditable.
GTM questions get answered without reconciliation overhead. When marketing and sales refer to the same account, they are drawing from the same canonical entity, resolved before either system ran its query. A question about which campaigns are driving pipeline in a specific territory answers from a single resolved data picture rather than a join across systems that produces different results depending on who runs it and when. The reliability of the answer is a function of the context layer, not the model's reasoning capability.
The cumulative effect is reaching the point at which AI recommendations become reliable enough that teams stop applying manual verification by default and begin acting on outputs with confidence. That shift is not a product capability. It is an architectural property built into the layer that prepares context, and it cannot be reached by improving the model or refining the prompt. It requires that the inputs to the model be resolved, consistent, and permissioned before inference begins.
How Sturdy solves this: The context layer, built for revenue data
Sturdy is the infrastructure that sits between your raw data sources and the model. It normalizes entities across Salesforce, Gmail, Slack, Zendesk, Jira, and other systems your revenue team already runs on, collapsing four different records for the same account into a single resolved entity before context assembly begins. Signal is compressed and classified before retrieval: Sturdy separates bug reports from feature requests from sentiment shifts, strips noise, and ensures the highest-signal content arrives first in the context window. Permissions are enforced at the retrieval boundary, not passed as prompt instructions. The model never receives records the caller cannot see, because exclusion happens upstream of inference, not inside it.
The architectural consequence is that the model's job becomes narrower and more reliable. It receives a context payload assembled from resolved, classified, permissioned inputs rather than a window full of fragments it must filter and reconcile before it can reason. That narrowing is what makes outputs traceable. When a recommendation can be challenged, the answer traces back through the context layer to specific signals, specific entities, and specific access decisions, all of which were resolved before the query ran.
The context layer also has a compounding property the model does not. Each source connected, each entity resolved, and each workflow built on top of it increases the coverage and resolution of the intelligence available to every future query. The model running on top of that layer in 2027 will be different from the one running today. The context layer will be the same one, with more accumulated resolution. That asymmetry helps explain why context infrastructure tends to retain value across model generations, while the models themselves continue to change.
.png)
Stop Making Board-Level Commitments Based on Opinions

If you're a CRO, does this sound familiar: you walk into a meeting, see a green dashboard, and ask for an update. You hear the happy ears story, accept a gut-feeling MEDPICC score, and only realize a deal was a zero once it slips from the quarter.
It is a brutal way to run a business.
You are making board-level commitments based on a rep's optimism that the deal is real.
But look, it is not your fault.
You are operating in a 1990s software paradigm, where you are forced to rely on human interrogation to extract data from your team.
You hired high-level strategists, but the current tools turn them into manual data entry clerks.
When they fudge the numbers or ignore the red flags, it is a survival mechanism.
They are drowning in the noise just as much as you are, and they are telling you what you want to hear because they do not have the receipts either.
If you want to stop the slip, you have to move from trusting the update to inspecting the evidence. Here is how we look at the modern deal review:
Prioritize the Receipts over the Narrative:
• If a rep says a deal is a lock, but the CRM is a desert with zero mentions of success metrics or IT contacts, the deal is a ghost.
• Stop asking for an update.
• Start asking for the timestamp of the last technical alignment. If it is not in the language of the customer, it did not happen.
Inspect the Intersection:
• Accidents happen at intersections. In your business, that is the handoff between sales and delivery.
• If your sales data does not link to your support tickets or your implementation logs, you are flying blind.
• You need to know if the buyer is actually talking to your technical team or if those promises were never documented.
Use a Reasoning Engine to Scan the Noise:
• You cannot manually read 800 emails for a single deal.
• It is humanly impossible.
• But Sturdy can.
Stop trusting the update. Start inspecting the evidence.
The Context Engine
Executive Summary
The Context Engine
The model is not the problem. In every enterprise AI deployment that has hit a production wall in 2026, the failure lives one layer down: in how data is prepared, permissioned, and delivered before the model ever begins reasoning. Model choice has become the wrong question. With Anthropic's Claude surpassing OpenAI in U.S. enterprise adoption (34.4% vs. 32.3%, Ramp AI Index, April 2026), the market has already moved on. The competition has shifted from the Reasoning Engine to the Context Engine.
While nearly every enterprise has deployed frontier models, most are paying a Hallucination Tax they cannot see on their P&L. For an organization with 1,000 knowledge workers, the 4.3 hours per employee per week spent manually verifying AI outputs (Forrester, 2025) equates to approximately $16.8 million in annual salary drain, calculated at a conservative $75 per fully-loaded hour. Multiply that across a global enterprise, and it maps to the $67.4 billion in documented AI hallucination losses recorded in 2024 alone (AllAboutAI, 2025). This is not a failure of the model. It is a failure of architecture.
This paper argues that the next phase of enterprise AI requires a Deterministic Intelligence Layer: infrastructure that normalizes, indexes, and permissions customer data before it reaches the model. Teams replacing token-heavy RAG workflows with deterministic, pre-indexed context are seeing substantial reductions in cost per task while dramatically improving retrieval precision and AI reliability. More importantly, they are crossing the Threshold of Action: the point where AI becomes trustworthy enough to move from surfacing insights to executing workflows.
Section 1
The New Benchmark: Claude's Enterprise Breakout Moment
The AI market just had its crossover moment. As of April 2026, more U.S. businesses pay for Anthropic's Claude than for any other AI model. 34.4% vs. 32.3% for OpenAI, according to the Ramp AI Index, which tracks actual spending across more than 50,000 companies. This isn't a survey about intent. It's purchasing data.
By March 2026, Anthropic was capturing 73% of first-time business AI buyers (Axios, March 2026). A year earlier, one in 25 businesses on Ramp's platform paid for Anthropic. Today, it's nearly one in three.
Enterprise buyers don't switch defaults on a whim. They switch when something is demonstrably working better for the work they actually need done.
The Model Is Not the Problem
Here is the harder truth underneath that adoption story. Despite the crossover, most enterprise AI deployments are not delivering.
Widespread adoption. Widespread underdelivery. Both things are true simultaneously.
The instinct in most organizations is to treat this as a model problem: switch providers, upgrade to the latest version, hire a prompt engineer. None of it moves the needle in any sustained way, because the model is not where the failure lives. Claude is a reasoning engine. A sophisticated one. But a reasoning engine can only reason over what it's given. And in most enterprise deployments, what's given is a mess. Fragments.
The Performance Ceiling
Every technical leader deploying Claude at scale hits the same wall. The demo works. The pilot looks promising. Then it moves toward production, and something breaks. Not catastrophically, but consistently. The AI misattributes an item to the wrong account. It summarizes a customer's history using stale data. It generates an output that sounds authoritative and requires 20 minutes of human verification before it can be trusted.
"Feed a world-class reasoning engine confident, well-structured garbage, and you get the same in return."
This is not a failure of reasoning capability. It is a failure of context architecture. The data required to generate reliable outputs, account history, communications, support activity, call transcripts, and operational metadata typically exists across fragmented systems with inconsistent normalization, disconnected permissions, and no canonical entity resolution layer tying it together.
Context Is the New Infrastructure
The companies pulling ahead in 2026 are not winning because they chose a better model. They are winning because they solved the harder problem underneath it: delivering clean, resolved, permission-aware context before the model ever begins reasoning.
- IT, Data, and Platform Engineering provide the Engine (Claude): a recurring operating expense. World-class reasoning, rented.
- RevOps, Data, and AI Teams provide the Map (the Deterministic Data Layer): a long-term asset. Customer intelligence, owned.
Claude is the current catalyst. The model market will keep moving. New releases, new providers, new pricing. What doesn't move is the underlying problem: fragmented, unresolved, improperly permissioned data. Deterministic context is the durable architecture. The organizations building it now will carry that advantage into every subsequent model generation.
Most organizations already have the engine. What they lack is the map.
Section 2
The Hallucination Tax: Why Fragmented Data Kills AI Performance
If the model isn't the problem, why are so many production-grade AI initiatives hitting a performance ceiling? The answer is the Hallucination Tax.
In 2024, hallucinations cost enterprises an estimated $67.4 billion in global losses (AllAboutAI, 2025). By early 2026, the cost has shifted from outright fabrications to "silent hallucinations": outputs that look structurally perfect but are factually untethered from the current state of the business.
For an organization with 1,000 knowledge workers, the 4.3 hours lost per person per week equates to roughly 223,600 hours of wasted annual productivity, approximately $16.8 million in annual salary drain at a conservative, fully loaded rate. It never appears on the P&L as an AI cost. It shows up as underperformance, missed forecasts, and slower deal cycles.
This forces employees to act as "Human Middleware": the bridge between fragmented systems and the AI that was supposed to make them irrelevant. This tax is the direct result of four specific architectural failure modes.
Failure Mode 1: Retrieval Precision (The Token Tax)
Standard RAG is probabilistic. It retrieves semantically similar fragments, not operational truth. When a sales leader asks, "Why did we lose this seven-figure deal?", the system may surface an old QBR deck instead of the pricing objections in email, the procurement concerns buried in Slack, the legal escalation in Jira, and the product gaps discussed in call transcripts that actually determined the outcome.
Because retrieval is imprecise, teams over-index by stuffing the context window with every possible document to ensure the right one is in there. The result: thousands of reasoning tokens spent filtering noise. A world-class reasoning engine doing the work of a search index.
Failure Mode 2: "Lost in the Middle" (Attention Drift)
Research by Liu et al. (TACL, 2024) demonstrated that accuracy on multi-document reasoning tasks drops by more than 30 percentage points when relevant information is buried in the middle of a long context window. This matters enormously in enterprise environments, where critical signals are scattered across support escalations, pricing discussions, call transcripts, Slack threads, and CRM updates. Simply increasing context size does not solve the problem. In many cases, it amplifies it by forcing the model to attend to more noise.
Failure Mode 3: The Identity Crisis (Entity Disambiguation)
In a fragmented environment, identity is a variable, not a constant. "Jane Doe" in a Zoom transcript needs to resolve to the same Jane Doe in Salesforce, Gmail, Zendesk, Slack, and the CRM activity timeline. Without deterministic entity resolution, the model is forced to infer whether those interactions belong to the same person, account, or buying committee.
Without deterministic entity resolution, the model is forced to reconstruct identity probabilistically. A support escalation tied to one stakeholder, a pricing objection raised in a sales call, and an executive concern discussed over email may be incorrectly assembled into the wrong account narrative entirely.
Failure Mode 4: The Permission Ghost (Unauthorized Surface)
This is the silent killer of enterprise AI programs. Most RAG pipelines lack Source-System Parity. If the AI retrieves a snippet from a private executive email because it was "semantically relevant" to an intern's query, the system has failed regardless of whether anyone noticed.
Incidents like EchoLeak show exactly why retrieval-layer permission enforcement matters. In late 2025, researchers demonstrated a zero-click vulnerability in Microsoft 365 Copilot that could exfiltrate sensitive data from Copilot context without user interaction. No prompt injection required. The retrieval layer was the attack surface.
For most organizations, the permission layer isn't just a technical problem. It is an organizational liability that Legal and Security will eventually force you to solve on a deadline, under pressure, after something has already gone wrong.
The Production Wall
These four failure modes create the Production Wall. A curated demo can appear remarkably accurate. But production environments are not curated. They are noisy, fragmented, and constantly changing, with critical signals distributed across emails, calls, support threads, Slack conversations, and operational systems evolving in real time.
"You cannot solve these four problems by tuning the prompt. You have to solve them by fixing the context."
Section 3
The Deterministic Intelligence Layer
To climb over the Production Wall, enterprise architecture must evolve. The solution is not a larger context window or a more complex prompt. It is a fundamental shift in how data is prepared for the model. Enter the Deterministic Intelligence Layer: infrastructure that sits between your raw data silos and Claude, acting as the architectural antidote to the four failure modes in Section 2.
The Four Pillars
1. Precision Indexing (Ending the Token Tax)
Instead of relying on similarity search alone, the context layer resolves entities, removes duplication, and prioritizes high-signal interactions before retrieval. The model receives structured operational context rather than raw fragments competing for attention.
In Sturdy-observed deployments, replacing raw context with pre-indexed, distilled payloads has reduced token consumption by 80 to 90% on comparable workflows. Results vary by source data density and baseline architecture. You stop paying for Claude to be a search filter.
2. Signal Distillation (Solving "Lost in the Middle")
Semantic Pruning strips HTML headers, Slack noise, legal footers, and the RE: FWD: RE: reply chains that bury every actual decision in 40 lines of quoted text, distilling threads into thematic buckets: Bug Reports, Feature Requests, Sentiment Shifts. The most critical insights land at the beginning of the context window, bypassing the 30-point accuracy drop documented in long-context research.
3. Deterministic Entity Resolution (Fixing the Identity Crisis)
A Global Entity Map resolves disparate naming conventions into a single, immutable Customer ID. Claude is no longer guessing whether two conversations belong to the same account. It is being told they do.
4. Parity-Enforced Permissions (Exorcising the Permission Ghost)
The retrieval layer enforces source-system permissions before context assembly, so unauthorized records are excluded from the payload sent to the model. This is not a prompt-level instruction that can be overridden or confused. It is an architectural enforcement point that sits entirely upstream of the model.
Security becomes a structural property of the architecture, not a probabilistic instruction to the model. Incidents like EchoLeak show why this distinction matters: when permission logic lives inside the prompt, the retrieval layer remains an attack surface. When it lives at the data layer, it doesn't.
Reference Implementation: Sturdy + Claude via MCP
While the merits of this architecture are clear, building it internally results in years of maintenance debt (see Section 5). Sturdy leverages the Model Context Protocol to serve as the Context Engine for Claude, normalizing, indexing, and permission-stamping your customer intelligence layer across Salesforce, Gmail, Slack, and Zendesk before Claude ever queries it.
Claude provides the Reasoning Layer. Sturdy provides the Memory and Context Layer. Together, they move an enterprise from AI that reads your business to AI that acts on it.
Section 4
What It Unlocks: From Reading to Acting
In 2026, summarization is a commodity. The competitive advantage lies in moving from AI that reads your business to AI that acts on it. This transition requires a fundamental shift in how leadership views the AI stack and who owns what.
- IT, Data, and Platform Engineering provide the Engine (Claude): recurring operating expense. World-class reasoning, rented.
- RevOps, Data, and AI Teams provide the Map (the Deterministic Data Layer): a long-term asset. Customer intelligence, owned, not rented.
When the engine has a perfect map, the Acceleration Gap closes.
RevOps: The Revenue Architect
For the RevOps leader, a deterministic layer turns fragmented operational data into active revenue signals. Instead of building static dashboards that explain why a quarter was missed, RevOps can monitor the commercial signals that actually move deals: pricing hesitation in email, procurement delays, legal friction, competitive mentions, executive disengagement, stalled next steps, and tone changes across active opportunities.
A deterministic context layer resolves those signals to the right person, account, opportunity, and timeline before AI ever reasons over them. That is what turns scattered communication into reliable revenue action.
RevOps stops being a report generator. It becomes the operating system for revenue execution: designing the logic that turns verified commercial signals into coordinated GTM action.
Sales: Instant Account Intelligence
The average sales rep spends roughly 20% of their week on pre-call research. With a deterministic layer, the account briefing is no longer a probabilistic summary. It is a verified snapshot: "The customer's last three support tickets were resolved, but they haven't yet implemented the API update discussed in the March QBR."
Product: The Automated Feedback Loop
Product managers are often the most data-rich but insight-poor employees in the company. A deterministic layer moves PMs from reading feedback to querying insights. Claude analyzes 60 days of feedback across Slack and Zendesk and, with a single prompt, generates a high-fidelity Jira ticket including exact customer quotes, impacted account IDs, and revenue at risk.
Customer Success: Proactive Triage
In CS, latency is the enemy. A deterministic layer allows Claude to perform live triage. When a customer sends a frustrated email, the AI checks contract terms and recent product usage logs before the CSM has finished reading the subject line. It presents a Context-Aware Response ready to send, grounded in verified account data.
"The model you license today is rent. The customer intelligence layer you build is equity. One gets replaced. The other compounds."
Every account signal normalized, every entity resolved, every permission enforced. That accumulates. The organizations building this layer now are building institutional memory that makes every model they run on top of it better.
Section 5
The Build vs. Buy Reality
The instinct for most sophisticated IT and data teams is to build. It is a legitimate impulse. The stack looks deceptively simple: a few API connectors, a vector database, and some chunking logic. In the demo phase, an internal build often feels like the most cost-effective path.
The Four Hidden Engineering Hurdles
1. The Normalization Treadmill
Building a connector to Salesforce is straightforward. Maintaining the logic layer that resolves entity names across Salesforce, Slack, and Zendesk as those systems' schemas evolve is a full-time engineering job. This is Semantic Drift: hundreds of developer hours consumed by maintenance rather than innovation.
2. The Permission Mapping Paradox
Mapping row-level permissions from source systems into an AI context window is one of the most complex security challenges in modern software. Most internal builds rely on prompt-level security, which fails under the weight of incidents like EchoLeak. This isn't a technical trade-off. It is an organizational liability waiting to be forced into crisis.
3. The Latency Wall
A custom RAG pipeline often takes 5 to 10 seconds to fetch and clean data. In Sturdy-observed deployments, pre-indexed deterministic retrieval consistently operates under 1 second on production data volumes, but reaching that benchmark requires specialized search infrastructure expertise that is rarely the core competency of a generalist data team building from scratch.
4. The Token Optimization Tax
Without signal distillation, internal builds routinely pass 3x to 5x more tokens than necessary. Teams save on build costs only to spend twice as much on model API costs.
Where Does Your Engineering Dollar Go?
The strategic question isn't "Can we build this?" It's "Should we own the maintenance of this?"
Competitive advantage does not live in the plumbing. No customer chooses a vendor because their AI has a better Python script for cleaning Slack data.
By offloading the Normalization Treadmill to Sturdy, organizations are promoting their engineering teams from Data Cleaners to AI Product Owners, moving their best people away from the maintenance treadmill and toward the high-value work of building AI that drives revenue.
Buy the plumbing. Build the logic. The teams doing this are shipping revenue-generating AI workflows, while their competitors are still debugging entity-resolution scripts.
Section 6
What to Do Now: The 2026 Roadmap
The Acceleration Gap is not a permanent state. It is a choice of architecture. The move is not to wait for a smarter model. The move is to fix the context. Here are four moves for leadership to take in the next 90 days.
Move 1: Audit Your Retrieval Precision, Not Your Prompts
Most teams spend the majority of their time prompt-tuning errors caused by bad data retrieval. The action: Run a Ground Truth test. Take ten complex customer queries and manually check the data fragments Claude is being fed. If more than 20% of that data is noisy, stale, or misattributed, no prompt engineering will save the deployment. You have a plumbing problem, not a reasoning problem.
Move 2: Isolate a Multi-Source Workflow
The highest ROI for a deterministic layer is found where data is most fragmented. The action: Pick a high-value, closed-loop use case where data lives in at least three systems. For example: the path from customer feedback in Slack and Zendesk to an engineering action in Jira. Solve the context problem here, and you've built a blueprint for the rest of the organization.
Move 3: Enforce Permissions at the Data Layer
Stop treating security as a probabilistic instruction. The action: Move permission enforcement out of the system prompt and into the retrieval infrastructure. Ensure the retrieval layer enforces source-system permissions before context assembly, so unauthorized records never reach the model. The Permission Ghost is exorcised structurally, not instructionally, and the organizational liability is removed before Legal ever has to get involved.
Move 4: Define Where AI Earns the Right to Act
The distance between AI that summarizes and AI that executes is a trust gap, not a technology gap. The action: Build human-in-the-loop approval gates for high-stakes actions. Drafting a renewal contract. Creating a Jira ticket. Sending a support response. Use your deterministic layer to provide the required Confidence Equity. The threshold to target is a sub-5% error rate on AI-generated drafts. That is the point at which approval gates can be safely reduced, and workflows become self-sustaining.
Traditional probabilistic RAG architectures struggle to reach this threshold consistently at enterprise scale. Because probabilistic retrieval introduces entity errors, stale data, and permission noise, error rates on complex multi-source tasks typically stabilize in the 15 to 30% range regardless of prompt quality, even with hybrid retrieval and reranking layers added on top.
A deterministic layer that resolves entities before inference, distills the signal before retrieval, and enforces permissions before the model ever sees the data is the only architecture that makes sub-5% structurally achievable, rather than an occasional lucky outcome.
In Sturdy-observed deployments, teams that reach this threshold have consistently moved to reduced-oversight approval workflows within a quarter. Results depend on workflow complexity and baseline data quality. Reaching the sub-5% Trust Threshold is the definitive signal that an organization has graduated from "AI Experiments" to a Context Engine architecture capable of autonomous action. That is the architectural line between AI that assists and AI that acts.
Conclusion
The Architectural Advantage
Frontier models will continue to improve and commoditize. The durable advantage is no longer the model itself. It is the architecture surrounding it.
The long-term value does not live in another standalone AI interface. Interfaces change too quickly. The durable layer is the operational context infrastructure beneath them.
Organizations that solve deterministic context assembly, entity resolution, permission-aware retrieval, and operational state assembly gain a compounding advantage independent of whichever model, interface, or orchestration layer dominates next year.
Organizations that solve context architecture today are building infrastructure that compounds across model generations. As interfaces evolve and models improve, the operational context layer beneath them becomes increasingly valuable.
"The era of the Context Engine is here. Is your architecture ready for it?"

Your AI isn’t the problem. Your data is.
IT leaders may have resisted AI early, but that phase passed quickly. The real concern wasn’t whether to use it. It was how to control it. Governance, security, visibility. In the end, it came down to preventing sensitive work from being done in personal accounts. Reasonable.
So they got comfortable, signed off, and rolled it out. ChatGPT, Copilot, Claude, company-wide, with guardrails.
People are using it. That part worked.
The disappointment
The problem is what revenue leaders are finding now that it’s live.
The data they actually want to use isn’t accessible in any meaningful way. And that matters more than most people realize, because LLMs are only as useful as what you put in front of them. They’re exceptional at reasoning over structured, coherent information. They’re not designed to reconcile fragmented, inconsistent data spread across a dozen systems.
Nobody’s model is.
So instead, people compensate.
They cut and paste. Drop in exports. Upload a batch of emails and call transcripts, and hope coherence comes out the other side.
It doesn’t. They get fragments. Plausible-sounding ones, but fragments.
The diagnosis
What commercial leaders are running into isn’t a model problem. It’s a data problem.
The data they actually care about isn’t unified. It lives across email, Slack, Zoom, support tickets, calls, and CRM notes. Different systems. Different formats. No shared identity. No relationship context.
Even with connectors. Even with MCPs.
Because underneath it all, the data isn’t organized in a way a model can reason on. There’s no canonical view of the world.
The model doesn’t know that the same person shows up in Zoom, Slack, Zendesk, and Salesforce. It doesn’t understand that those interactions belong to the same thread, the same account, the same moment in a relationship.
So it fills in the gaps.
Not because it’s weak. Because it has to keep trying.
The gap
Meanwhile, the models themselves have gotten amazingly powerful. Reasoning is sharper than it’s ever been and getting better daily.
But the data layer most companies are feeding them? Still immature.
According to MIT’s 2025 State of AI in Business, over 80% of companies have explored or deployed LLMs, but only around 5% are seeing meaningful business impact.
High adoption. Low transformation.
That’s not a model problem.
What’s possible
What it looks like when this actually works is different.
Not dashboards. Not reports. Not exports.
A conversation. Like having the best revenue ops analyst you’ve ever worked with on call, one who has read every email, sat in on every call, and never forgets anything.
You ask: “Which accounts have shown signs of churn risk in the last 90 days?”
And instead of a guess, you get a ranked list. Accounts. ARR. The exact messages where the signal showed up. What changed. What triggered it. What to do next.
So you ask a follow-up: “Which of these are new customers?”
Now you’re looking at onboarding breakdowns. Common threads. Where the process is failing.
So you keep going: “Where are we missing expansion opportunities?”
And it surfaces accounts where someone said, “We’re thinking about rolling this out to another team.” But nothing was logged. No opportunity created. No follow-up.
That’s the shift.
You’re no longer stitching together context. You’re interrogating it.
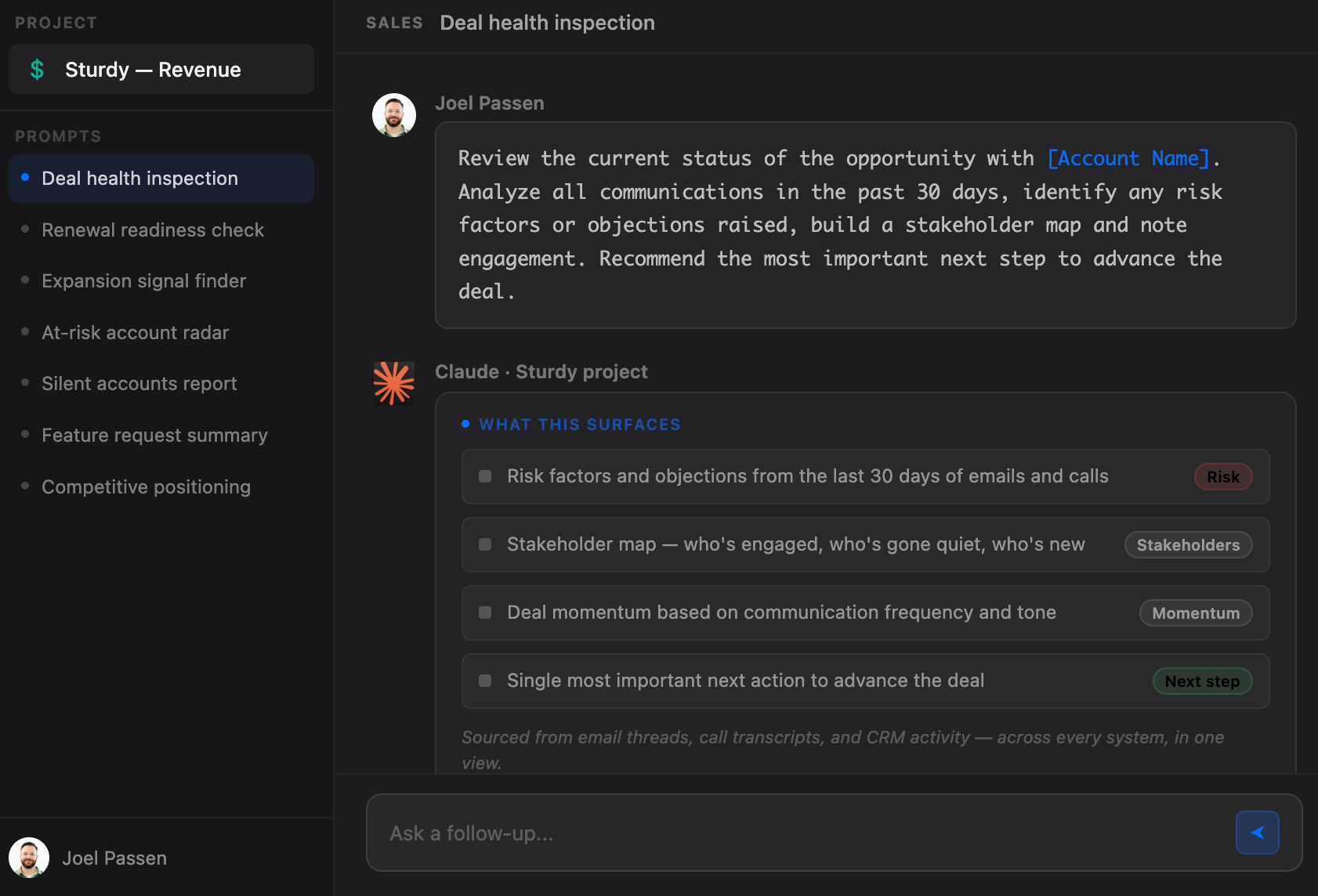
What changes
What changes when you fix the data layer, when your commercial data is normalized, deduplicated, and accessible, isn’t just speed.
It’s the level of questions you can ask.
These aren’t dashboard queries. They’re judgment calls. The kind that used to require a senior operator spending a weekend in spreadsheets and Salesforce. When your data layer is clean and the model has real context to work with, they become a 90-second conversation.
That’s the difference. Not a better model. A better fuel.
The data infrastructure reality
Most teams won’t get there by accident. The infrastructure problem is real: identity resolution across systems, conversation reconstruction across channels, deduplication, and signal enrichment. It’s six to twelve months of plumbing if you build it yourself.
The companies that crack it first won’t just be more efficient. They’ll be operating with a fundamentally different information advantage. They’ll see churn coming, spot expansion signals, catch friction early, before any of it shows up in the numbers.
At that point, the question changes.
It’s not whether AI works.
It’s whether your data is ready for it.
And whether you’re going to build that layer, or keep working around the absence of it.
This is what we're building at Sturdy.ai. The data layer your LLM actually needs.
.png)
The Moment B2B Sales Teams Forget Everything They Learned During the Deal
It’s not the close. It’s not the kickoff call. It’s the 48 hours in between — when the contract gets signed, the champagne (metaphorically) gets popped, and everything the sales team learned over months of conversations, negotiations, and relationship-building quietly disappears.
The delivery team inherits a contract and a few CRM notes. Not the story behind the deal.
This is the handoff problem. And it’s costing companies more than they realize.
Why the Knowledge Dies at the Signature Line
Think about what actually happens during a complex B2B sale.
Over weeks or months, a sales team accumulates an extraordinary amount of institutional knowledge. They learn why the buyer is actually moving now — not the official reason, but the real one. The compliance incident that became a board-level conversation. The internal champion who’s been pushing for change for two years and finally got budget. The exec who’s skeptical and needs to see a specific proof point before they’ll get on board.
They learn who matters and how decisions actually get made, which is almost never what the org chart suggests. They learn what got promised in the final stretch: the SLA clause that got added at the last minute, the integration that’s now contractually locked, the go-live date that the CFO has already presented to her board.
None of that lives in the CRM. It lives in emails, call recordings, Slack threads, and people’s heads.
And the moment the deal closes, the sales team moves on to the next one. That’s their job. That’s how they get paid. But the institutional knowledge they spent months building the context that would let an implementation team start informed, instead of starting over, largely evaporates.
Onto the next pipeline review.
The Cost Nobody Is Measuring
Companies measure churn. They measure NPS. They measure time-to-value.
Most don’t measure the cost of the knowledge gap at handoff — because it doesn’t show up as a line item. It shows up as implementation delays. Escalations. Customers who feel like they have to repeat themselves six months into a relationship that should already be mature.
It shows up as promises made during the sale that nobody on the delivery side knew about. Commitments that surface in month three as a nasty surprise. Expectations that were set in a negotiation conversation that never made it into a system anyone on the CS team can see.
The SaaS industry has spent a decade optimizing the top of the funnel. Sophisticated systems for capturing and qualifying demand. Playbooks for every stage of the sales motion. Entire conferences dedicated to pipeline hygiene.
And then we hand a contract and a prayer to the team responsible for actually delivering the value we sold.
What Good Looks Like
I’ll make this concrete.
We recently ran Sturdy against a real deal, a $190K ACV implementation that had just closed. Board-level compliance incident drove the urgency. CFO was the economic decision-maker: analytical, direct, not interested in being charmed. An integration was contractually locked in Exhibit A. Timeline slippage wasn’t just an ops problem; it would retrigger board scrutiny because of the prior incident.
The implementation team knew all of that before the first kickoff call.
Not because someone wrote a perfect handoff email at 11 pm the night before go-live. Because Sturdy read across the entire deal — emails, calls, negotiations — and surfaced the context that actually matters: why they bought, who really matters internally, what was promised, and where the risk lives.
That’s the brief I show in the video. Notice how specific it is. Notice that it doesn’t just describe what happened, it tells the delivery team what to do with it.
That’s what institutional knowledge looks like when it doesn’t get lost.
The Broader Shift
The handoff problem is really a symptom of something larger.
B2B revenue has always been a team sport — sales, CS, implementation, product, and finance all own a piece of the outcome. But the systems we’ve built treat each function as a silo. Data gets entered into the CRM by whoever remembered to do it. Calls get recorded and filed somewhere nobody looks. Emails pile up in inboxes that get searched only when something’s already on fire.
The signals are there. The context exists. It’s just buried, and it disappears at exactly the moments in the customer lifecycle when it’s most needed.
The companies that figure this out and build systems to capture, preserve, and operationalize institutional knowledge across the revenue lifecycle will have an operational advantage over those still relying on heroic individual effort and the hope that someone wrote a good handoff doc.
This isn’t an incremental improvement. It’s a different way of operating.
The moment a deal closes should be the moment an organization puts everything it learned to work.
Right now, for most companies, it’s the moment they forget it.
That’s the problem Sturdy was built to solve. If this resonates, start at sturdy.ai.

Sturdy's MCP Server: One Call. Every Source. Already Resolved.
Another Step to Unlocking AI Outcomes: Resolve the Data First
The bottleneck is not your AI model. It’s the data it has access to. Sturdy’s MCP server delivers pre‑resolved, canonically organized context so your LLM can reason over it instead of guessing around it.
Another Step to Unlocking LLM Outputs: Resolve the Data First
For years, the problem was that data lived in silos. Different systems for sales, support, and calls. But the worst offenders were email and Slack. Email isn’t one silo; it’s as many silos as there are people on your team. Every rep, every CSM, every exec running their own inbox, none of it visible to anyone else. Slack is no different. Conversations buried in channels and DMs that nobody ever sees again.
What Changes
"Your LLM now has a single, usable data layer any user can query to inspect the full context of every prospect and customer."
“Every team now works from a single view of the relationship, not fragments of it. Sturdy gets everyone on the same page, no matter what screen they use.”
MCPs were a material step forward. They give LLMs a standardized way to reach outside their context window and pull live data from external systems without a human copying it in manually. An account record, an open ticket, a call summary, all accessible at query time without a custom integration.
Today, teams are dealing with a different version of the same problem. Every MCP server exposes a slice of the picture. The LLM can pull structured records, read a ticket, or fetch a call summary. What it cannot do is answer a question that requires all of them at once, because the data across those systems was never resolved against each other.
The entities don’t match. The timeline is fragmented. The thread that started the conversation often isn’t there at all.
The question every revenue team actually needs answered isn’t “what does this system say about the account?” It’s the question that requires the full picture: what has every person at our company said to every person at this company, across every channel, and what does that tell us about where this relationship actually stands right now.
No single MCP server can answer that. Most LLMs, handed raw data, will approximate an answer and present it with false confidence. That’s not intelligence. It’s a good guess.
That answer doesn’t live in any single system. It lives in the relationship between all of them. And if the LLM has to call multiple MCP servers to piece it together, resolve duplicate records, and reassemble a coherent account state on every query, the fragmentation problem hasn’t been solved. It’s just been moved into the inference layer.
What Sturdy’s MCP Does
Sturdy ingests from all of it. Email, call transcripts, support tickets, Slack, CRM, and meeting tools. Every channel where communication happens.
Before any of that reaches an LLM, Sturdy does the work that makes it usable. Entities are deduplicated and matched to canonical records. Interactions are classified. Signals are enriched, permission‑scoped, and source‑referenced. The relationship between interactions across systems is established once upstream.
Not inferred at query time. Resolved in advance, maintained continuously, and auditable.
That last part matters more than it sounds. LLMs are getting better at fuzzy matching, but revenue decisions cannot rely on it. “Probably the same account” is not good enough when you’re making retention calls, forecast commits, or expansion bets.
Then Sturdy exposes all of it through a single MCP server. One call. Pre‑resolved context with citations. The LLM starts from the signal, not the raw material.
The Token Cost Nobody is Talking About
There’s a practical consequence to raw MCP that most teams haven’t priced in yet. When an LLM has to reconstruct account context from scratch on every query, it burns tokens doing work that shouldn’t need to happen at query time.
Pulling from multiple sources. Resolving conflicts. Traversing relationships. Figuring out what it’s looking at.
At low volumes, this is invisible. At scale, it isn’t. The rediscovery tax on a raw MCP call runs roughly 60 to 80 percent of total token consumption per query. That’s the LLM figuring out context, not reasoning over it.
Sturdy removes most of that overhead. The context arrives already structured. The LLM starts from a position of knowing. The inference budget goes toward answering the question, not reconstructing the data.
What This Means for Teams Building on it
Sturdy’s MCP is designed for teams that have already provisioned an LLM and are now trying to make it useful. CTOs deploying models across their organization. Heads of Data and AI are trying to get real answers out of them. Operations teams are building agents that need reliable account intelligence.
The properties that matter:
Canonically resolved
Entity deduplication and matching happen upstream. The same account appears as one account regardless of how many systems it lives in.
Permission‑aware
Access controls are baked into the data layer. What a user can see reflects what they’re authorized to see in the source systems.
Source‑referenceable
Every signal comes with a citation. When something surfaces, the underlying interaction is linked.
Model‑agnostic
The data layer doesn’t change based on which model you use.
Nobody wants to spend 12 to 18 months normalizing data before they can build something useful. Resolving that data upstream changes what your LLM can do on day one.
Talk to us about connecting Sturdy to your existing AI deployment.

What Is a QBR? (And Why Most of Them Are Broken)

Quarterly Business Reviews (QBRs) were invented with good intentions: get out of the weeds, meet with your customer, and align on outcomes every quarter.
In practice? Many QBRs have become 40-slide product monologues that take weeks to build, bore executives, and don’t change much of anything.
As Aaron Thompson argues in his widely shared post “QBRs are Stupid” [1], the traditional way we do QBRs is often more about checking a box than driving real business value. But when done right—and when modern tools are involved—a QBR (or more broadly, an “Executive Business Review”) can still be one of the highest leverage motions in Customer Success, Sales, and Account Management.
This post breaks down:
- What a QBR is (and what it’s supposed to be)
- Who uses QBRs and why they matter
- The traditional steps to creating a QBR
- How QBRs are evolving (less “quarterly,” more “business review”)
- How Sturdy.ai can run QBRs for any account in seconds—not hours or days
What Is a QBR?
A Quarterly Business Review (QBR) is a structured, typically executive-level meeting between a vendor and a customer to:
- Review business outcomes and value delivered
- Align on goals, strategy, and risks
- Agree on a plan for the next period (not always a quarter anymore)
Unlike a status meeting, a QBR is supposed to focus on outcomes, strategy, and impact, not tickets, small features, or sprint updates.
Industry bodies like TSIA (Technology & Services Industry Association) and customer success leaders (e.g., Gainsight, Winning by Design) have consistently emphasized that effective business reviews should be outcome-based, data-backed, and jointly owned by vendor and customer [2][3].
Who Are QBRs For?
QBRs are heavily used across:
- Customer Success (CS) / Account Management (AM)
- To prove ongoing value
- Reduce churn and expand accounts
- Align on adoption, usage, and business outcomes
- Sales / Strategic Accounts / Customer Directors
- To maintain executive relationships
- Surface expansion opportunities
- Show roadmap alignment to strategic initiatives
- Professional Services / Consulting / Agencies
- To connect deliverables to business impact
- Discuss ROI, timeline, and next phases
- Reset expectations where needed
- Product & Executive Teams
- To hear voice-of-customer at the highest level
- Validate product direction with strategic accounts
- Identify common themes and risks across the portfolio
In modern SaaS and B2B, QBRs have shifted from a “CS-only” ritual to a cross-functional motion that spans CS, Sales, Product, and Leadership [4].
Why QBRs Matter (When They’re Done Right)
When they’re not just slidedecks for slidedeck’s sake, QBRs can:
- Prove value
Tie your product directly to metrics your customer’s executives care about: revenue, cost savings, risk reduction, NPS, time-to-value. - Protect and grow revenue
Well-run business reviews correlate with higher renewal and expansion rates because they build trust and keep your solution aligned with evolving needs [2][5]. - Align on strategy and roadmap
They create formal space to talk about: “Where is your business going?” and “How does our roadmap support that?” - Surface risk early
Adoption gaps, champion turnover, budget changes—QBRs are where these get raised and addressed proactively.
The problem is not the idea of a QBR; it’s the way traditional QBRs are executed.
The Traditional QBR: Steps, and Where They Go Wrong
Let’s walk through the typical (old-school) QBR workflow and why it’s so painful.
Step 1: Define Objectives and Audience
What’s supposed to happen:
- Clarify the purpose of the review:
- Renewal risk?
- Proving ROI?
- Expansion discussion?
- Strategic alignment with a new initiative?
- Confirm who will attend: executive sponsors, day-to-day users, procurement, etc.
- Tailor the content to those people, not a generic template.
Why it matters:
McKinsey and Gartner both emphasize executive conversations that center on the customer’s business priorities, not your internal agenda [5][6]. If you don’t decide the objective and audience upfront, you end up with a “kitchen sink” deck that satisfies no one.
Where it goes wrong:
Teams often skip this step and reuse the same template for every account, regardless of size, segment, or lifecycle stage.
Step 2: Gather Data (Usage, Outcomes, Support, Voice-of-Customer)
What’s supposed to happen:
- Pull product usage data (logins, key feature adoption, utilization vs. license)
- Capture business outcomes (KPIs, ROI estimates, improved cycle times, etc.)
- Summarize support data (tickets, escalations, time-to-resolution)
- Incorporate voice-of-customer: NPS, CSAT, survey results, call notes, emails
Why it matters:
Data-backed QBRs are more credible and effective. TSIA’s research on outcome-based engagement models shows that value evidence (data plus narrative) is a core driver of renewal and expansion [2].
Where it goes wrong:
- Data is scattered across CRM, helpdesk, product analytics, call recordings, Slack, and email
- CSMs or AMs spend hours to days cobbling it together manually
- Important context (like that frustrated email from the VP last month) gets missed because it lives outside the “official” systems
Step 3: Build the QBR Deck
What’s supposed to happen:
A concise, outcome-focused structure such as:
- Executive Summary
- Key wins this period
- Key risks and challenges
- Recommended next steps
- Your Goals & Strategy
- Recap of the customer’s stated objectives
- Any changes in their business (M&A, leadership, budget shifts)
- Value & Outcomes
- KPI trends
- ROI or impact stories
- Before/after comparisons where possible
- Adoption & Usage
- Feature adoption
- Usage by segment/team
- Gaps and opportunities
- Support & Experience
- Ticket trends
- NPS/CSAT highlights
- Themes from feedback
- Roadmap & Alignment
- Relevant roadmap items
- How they map to the customer’s goals
- Joint Plan / Next 90 Days
- Clear action items, owners, and dates
- Milestones for the next review
Why it matters:
This structure keeps the meeting focused on the customer’s business—not on an endless product tour. Gainsight and other CS thought leaders consistently recommend an “outcomes-first” format that leads with business results, not feature lists [3].
Where it goes wrong:
- The deck is 40–60 slides of feature screenshots and charts
- The story is missing: data with no narrative, or narrative with no data
- It’s built from scratch every time, burning hours of CSM and AM bandwidth
Step 4: Internal Review and Alignment
What’s supposed to happen:
- CS, Sales, and sometimes Product or Leadership review the QBR deck together
- Align on:
- Renewal / expansion posture
- Risk areas to probe
- Who will say what in the meeting
Why it matters:
Cross-functional alignment ahead of the call means you present a unified front. Research on strategic account management underscores the importance of coordinated communication across all vendor stakeholders [7].
Where it goes wrong:
- Internal prep is rushed or skipped
- Different people show up with different agendas
- The customer experiences a fragmented, reactive conversation
Step 5: Run the Meeting
What’s supposed to happen:
- Start with outcomes and their priorities, not your agenda
- Spend more time on discussion than on presenting slides
- Ask questions like:
- “What’s changed in your business since we last met?”
- “What would make this partnership a no-brainer for you next year?”
- “Where are we falling short of expectations?”
Why it matters:
Harvard Business Review and other executive communication research shows that senior leaders want vendors to:
- understand their business context, and
- co-create solutions, not just present information [6].
Where it goes wrong:
- It’s a monologue; the vendor talks for 80–90% of the time
- The “review” is mostly a product tour or roadmap dump
- Action items are vague or never captured
Step 6: Follow-Up and Execution
What’s supposed to happen:
- Share a succinct recap:
- Decisions made
- Action items, owners, and due dates
- Updated success plan
- Track progress and refer back to it in the next review
Why it matters:
Without follow-up, QBRs become “nice conversations” that don’t change outcomes. TSIA and Forrester both highlight the importance of codifying customer outcomes and success plans as part of a recurring cadence [2][8].
Where it goes wrong:
- Notes live in someone’s notebook or a random doc
- No shared source of truth for the success plan
- The next QBR starts from scratch, again
How QBRs Are Evolving
Several trends are reshaping how leading teams approach QBRs:
1. From “Quarterly” to “Right Cadence”
Not every account needs a formal review every quarter. Many organizations now use:
- Tiered cadences:
- Strategic: monthly / quarterly
- Mid-market: 2–3x per year
- Long-tail: automated or one-to-many reviews
- Event-based reviews:
- Post-implementation
- Pre-renewal
- After major org or product changes
This aligns with best practices in scaled customer success, where engagement is driven by value moments and risk signals, not arbitrary calendar quarters [3][4].
2. From “Slide Deck” to “Shared Workspace”
Instead of a static PowerPoint, teams are moving toward:
- Live dashboards (usage, outcomes, health)
- Shared success plans (in CRM or CS platforms)
- Collaborative docs with real-time notes and ownership
The review becomes a conversation anchored in live data, not a one-way presentation of stale screenshots.
3. From “CS-Only” to Cross-Functional
Sales, Product, and Leadership are increasingly:
- Joining key business reviews
- Using them to validate roadmap, gather voice-of-customer, and shape account strategy
- Treating QBR artifacts as input into forecasting, product planning, and exec reporting
This shifts QBRs from a “CS ritual” to a company-wide motion for strategic accounts.
4. From Manual to AI-Accelerated
The most important evolution: how the QBR is created.
Instead of:
- Manually pulling data from 6+ systems
- Rebuilding decks from scratch
- Hoping someone remembered that critical email or call
Organizations are now using AI and automation to:
- Aggregate all customer interactions and signals
- Summarize risks, opportunities, and sentiment
- Auto-generate QBR-ready narratives and visuals
This is where tools like Sturdy.ai fundamentally change the game.
How Sturdy.ai Can Run QBRs for Any Account in Seconds
Traditional QBR prep can easily consume 5–10+ hours per account once you factor in:
- Data gathering
- Deck building
- Internal alignment
- Revisions
Multiply that across a CSM’s portfolio and it becomes obvious why QBRs either get skipped or watered down.
Sturdy.ai flips this on its head.
At a high level, Sturdy.ai:
- Ingests your real customer data
- Emails
- Call transcripts
- Support tickets
- CRM notes
- Product usage and other signals (where integrated)
- Understands what matters
- Themes and topics (requests, bugs, risk signals)
- Sentiment and urgency
- Stakeholder changes and escalation patterns
- Outcome-related language (ROI, time savings, revenue impact, etc.)
- Auto-builds QBR-ready insights in seconds
For any account, Sturdy.ai can surface:- What’s going well (wins, positive feedback, adoption signals)
- What’s not (repeated complaints, unresolved issues, risk indicators)
- Which outcomes you’ve actually helped drive
- Concrete recommendations and action items for the next period
- Generates QBR artifacts instantly
Instead of starting with a blank slide, you start with:- An executive summary tailored to that account
- Key metrics and trends pulled from your systems
- Highlighted quotes and examples from real interactions
- A suggested agenda and next-steps section
What used to take hours or days of manual prep becomes a seconds-long operation:
“Run QBR for ACME Corp.”
…and you have a structured, account-specific review ready to refine and deliver.
Why This Matters for Modern CS, Sales, and Account Teams
When QBRs are no longer time-prohibitive:
- You can run them for more accounts, not just the top 10%
- You focus on quality of conversation, not on slide assembly
- You capture real, holistic context, not just what’s in one system
- You can standardize excellence, instead of relying on heroics from your best CSMs
Instead of asking, “Do we have time to do a QBR for this customer?”, the question becomes:
“Given we can generate a review in seconds, what’s the right cadence and format for this account?”
That’s the shift from QBRs-as-admin-work to QBRs-as-a-strategic-advantage.
Bringing It All Together
- QBRs were created to align on outcomes, prove value, and co-create a plan—not to be product demos with extra steps.
- Traditional QBRs are broken because they’re manual, generic, and often misaligned with what executives actually care about.
- The fundamentals still matter: clear objectives, data-backed story, joint success plan, and strong follow-up.
- QBRs are evolving toward flexible cadence, collaborative formats, cross-functional ownership, and heavy use of data and AI.
- With Sturdy.ai, you can run QBRs for any account in seconds, pulling from the full reality of your customer interactions—not just the few metrics someone had time to find.
If you’re spending hours or days preparing for each QBR, you’re paying the “old tax” on a motion that no longer has to be that painful. The value of the QBR is in the conversation, not the manual labor behind the slides.
References
[1] Aaron Thompson, “QBRs are Stupid,” LinkedIn Pulse (discussion of common QBR pitfalls and how they fail to deliver real value).
[2] TSIA (Technology & Services Industry Association), research and best practices on outcome-based customer engagement and Customer Success motions.
[3] Gainsight, Customer Success thought leadership on Executive Business Reviews and outcome-focused customer engagement.
[4] Winning by Design and similar SaaS consulting frameworks on recurring value reviews and customer-centric cadences.
[5] McKinsey & Company, research on B2B customer value, account management, and executive engagement strategies.
[6] Harvard Business Review and Gartner, articles and research on effective executive conversations and strategic vendor relationships.
[7] Strategic account management literature and SAM programs that emphasize coordinated, cross-functional engagement with key customers.
[8] Forrester, research on customer lifecycle management and the importance of measurable, recurring value communication.
.png)
The Most Dangerous Threat to CROs
The most dangerous threat to CROs doesn’t live in the opportunity pipeline.
It's churn.
- It doesn’t scream like a missed quarterly pipeline goal.
- It doesn’t show up in dashboards until it’s too late.
- It's rarely caught by a generic 'health score'.
- It's the board meeting killer.
Retaining and growing our customers is the only repeatable, compounding, capital-efficient growth lever left in B2B businesses.
📉 CAC is way up.
📉 Channels are saturated.
📉 Talent is expensive.
📉 Competition is fierce.
📉 Switching costs are low.
The path to $100M used to be “sell, sell, sell.”
Today? It’s “land, retain, expand.”
No matter how strong your sales motions are or how slick your product or service looks during the sales process, if your customers are churning, you’re stuck in a leaky bucket loop of doom.
Every net-new dollar you win is offset by dollars you lose. It's just math.
Yet most GTM orgs still operate like retention is someone else’s problem. "That's a CS thing."
- The CS team might “own” the customer post-sale.
- Account Management may own the renewal and growth number.
- Support is in the foxhole on the front line.
- RevOps might model churn with last quarter’s data.
- Marketing might send an occasional newsletter via email.
- Finance may be leaning in on the forecasting.
- Product is building things that supposedly the customers want.
But in reality, churn is the CRO's problem. We wear it - or should.
If your go-to-market motion isn’t designed to protect and grow customers from Day 1, you’re not just leaving money on the table — you’re setting fire to it.
Retention and expansion aren’t back-end functions. They’re front-and-center revenue motions.
The most valuable work these days starts after the contract is signed — not before.
We need to stop treating post-live as a department and start treating it as the engine of durable growth.
.png)
Have you heard this from your CEO?
"How are we using AI internally?"
The drumbeat is real. Boards are leaning in. Investors are leaning in. Yet, too many leaders hardly use it. Most CS teams? Still making excuses.
🤦🏼 "We’re not ready."Translation: We don't know where to start, so I'm waiting to run into someone who has done something with it.
🤦🏼 "We need cleaner data."Translation: We’re still hoping bad inputs from fractured processes will magically produce good outputs. Everyone's data is a sh*tshow. Trust me. 🤹🏼♂️ "We're playing with it."Translation: We have that one person messing with ChatGPT - experimenting.
😕 "Just don't have the resources right now."Translation: We're too overwhelmed manually building reports, wrangling renewals, and answering tickets forwarded by the support teams.
🫃🏼 "We've got too many tools."Translation: We’re overwhelmed by the tools we bought that created a bunch of silos and forced us into constant app-switching.
🤓 "Our IT team won't let us use AI."Translation: We’ve outsourced innovation to a risk-averse inbox.
It's time to put some cowboy under that hat 🤠 . No one’s asking you to rebuild the data warehouse or perform some sacred data ritual. You don’t need a PhD in AI.
You can start small.
Nearly every AI vendor has a way for you to try their wares without hiring a team of talking heads to perform unworldly 🧙🏼 acts of digital transformation.
Where to start.
✔️ Pick a use case that will give you a revenue boost or reveal something you didn't know about your customers.
✔️ Choose something that directs valuable work to the valuable people you've hired.
✔️ Pick something with outcomes that other teams can use.
Pro Tip: Your CEO doesn't care about chatbots, knowledgebase articles, or things that write emails to customers.
What do you have to lose? More customers? Your seat at the table?
.png)
Talent gets you started. Infrastructure gets you scale.
We obsess over hiring A-players. But even the best GTM talent will flounder if the foundation isn’t there.
I’ve seen companies overpay for “rockstars” who quit in 6 months—not because they weren’t capable, but because they were dropped into chaos. No ICP. Bad data. No process. No enablement. No system to measure or coach.
Great GTM teams aren’t built on purple squirrels. They’re built on a strong foundation.
That foundation looks like this:
✅ A crisp, written ICP and buyer persona (not just tribal knowledge)
✅ Accurate prospect data to target the right ICP
✅ A playbook that outlines how you win—and how you lose
✅ A clear point-of-view that your team can rally around in every email, call, and deck
✅ Defined stages, handoffs, and accountability across marketing, sales, CS
✅ A baseline reporting system to see what’s working—and what’s not
When this exists, you can onboard faster, coach better, and scale smarter. It's not easy, and it’s not sexy, but it works.
Want to cut CAC and increase ramp speed? Start with your infrastructure. Hire into a structure.
You don't have 12 months to build this from scratch.
Connect what customers say to why your numbers move. Contextual revenue intelligence, ready for any LLM — or running natively in Ask Sturdy from day one.