Welcome to the Sturdy Blog
News and Resources
The latest from Sturdy — product news, insights, and resources.
.png)
The Context Engine
Executive Summary
The Context Engine
The model is not the problem. In every enterprise AI deployment that has hit a production wall in 2026, the failure lives one layer down: in how data is prepared, permissioned, and delivered before the model ever begins reasoning. Model choice has become the wrong question. With Anthropic's Claude surpassing OpenAI in U.S. enterprise adoption (34.4% vs. 32.3%, Ramp AI Index, April 2026), the market has already moved on. The competition has shifted from the Reasoning Engine to the Context Engine.
While nearly every enterprise has deployed frontier models, most are paying a Hallucination Tax they cannot see on their P&L. For an organization with 1,000 knowledge workers, the 4.3 hours per employee per week spent manually verifying AI outputs (Forrester, 2025) equates to approximately $16.8 million in annual salary drain, calculated at a conservative $75 per fully-loaded hour. Multiply that across a global enterprise, and it maps to the $67.4 billion in documented AI hallucination losses recorded in 2024 alone (AllAboutAI, 2025). This is not a failure of the model. It is a failure of architecture.
This paper argues that the next phase of enterprise AI requires a Deterministic Intelligence Layer: infrastructure that normalizes, indexes, and permissions customer data before it reaches the model. Teams replacing token-heavy RAG workflows with deterministic, pre-indexed context are seeing substantial reductions in cost per task while dramatically improving retrieval precision and AI reliability. More importantly, they are crossing the Threshold of Action: the point where AI becomes trustworthy enough to move from surfacing insights to executing workflows.

Section 1
The New Benchmark: Claude's Enterprise Breakout Moment
The AI market just had its crossover moment. As of April 2026, more U.S. businesses pay for Anthropic's Claude than for any other AI model. 34.4% vs. 32.3% for OpenAI, according to the Ramp AI Index, which tracks actual spending across more than 50,000 companies. This isn't a survey about intent. It's purchasing data.
By March 2026, Anthropic was capturing 73% of first-time business AI buyers (Axios, March 2026). A year earlier, one in 25 businesses on Ramp's platform paid for Anthropic. Today, it's nearly one in three.
Enterprise buyers don't switch defaults on a whim. They switch when something is demonstrably working better for the work they actually need done.
The Model Is Not the Problem
Here is the harder truth underneath that adoption story. Despite the crossover, most enterprise AI deployments are not delivering.

Widespread adoption. Widespread underdelivery. Both things are true simultaneously.
The instinct in most organizations is to treat this as a model problem: switch providers, upgrade to the latest version, hire a prompt engineer. None of it moves the needle in any sustained way, because the model is not where the failure lives. Claude is a reasoning engine. A sophisticated one. But a reasoning engine can only reason over what it's given. And in most enterprise deployments, what's given is a mess. Fragments.
The Performance Ceiling
Every technical leader deploying Claude at scale hits the same wall. The demo works. The pilot looks promising. Then it moves toward production, and something breaks. Not catastrophically, but consistently. The AI misattributes an item to the wrong account. It summarizes a customer's history using stale data. It generates an output that sounds authoritative and requires 20 minutes of human verification before it can be trusted.
"Feed a world-class reasoning engine confident, well-structured garbage, and you get the same in return."
This is not a failure of reasoning capability. It is a failure of context architecture. The data required to generate reliable outputs, account history, communications, support activity, call transcripts, and operational metadata typically exists across fragmented systems with inconsistent normalization, disconnected permissions, and no canonical entity resolution layer tying it together.
Context Is the New Infrastructure
The companies pulling ahead in 2026 are not winning because they chose a better model. They are winning because they solved the harder problem underneath it: delivering clean, resolved, permission-aware context before the model ever begins reasoning.
- IT, Data, and Platform Engineering provide the Engine (Claude): a recurring operating expense. World-class reasoning, rented.
- RevOps, Data, and AI Teams provide the Map (the Deterministic Data Layer): a long-term asset. Customer intelligence, owned.
Claude is the current catalyst. The model market will keep moving. New releases, new providers, new pricing. What doesn't move is the underlying problem: fragmented, unresolved, improperly permissioned data. Deterministic context is the durable architecture. The organizations building it now will carry that advantage into every subsequent model generation.
Most organizations already have the engine. What they lack is the map.
Section 2
The Hallucination Tax: Why Fragmented Data Kills AI Performance
If the model isn't the problem, why are so many production-grade AI initiatives hitting a performance ceiling? The answer is the Hallucination Tax.
In 2024, hallucinations cost enterprises an estimated $67.4 billion in global losses (AllAboutAI, 2025). By early 2026, the cost has shifted from outright fabrications to "silent hallucinations": outputs that look structurally perfect but are factually untethered from the current state of the business.
For an organization with 1,000 knowledge workers, the 4.3 hours lost per person per week equates to roughly 223,600 hours of wasted annual productivity, approximately $16.8 million in annual salary drain at a conservative, fully loaded rate. It never appears on the P&L as an AI cost. It shows up as underperformance, missed forecasts, and slower deal cycles.

This forces employees to act as "Human Middleware": the bridge between fragmented systems and the AI that was supposed to make them irrelevant. This tax is the direct result of four specific architectural failure modes.
Failure Mode 1: Retrieval Precision (The Token Tax)
Standard RAG is probabilistic. It retrieves semantically similar fragments, not operational truth. When a sales leader asks, "Why did we lose this seven-figure deal?", the system may surface an old QBR deck instead of the pricing objections in email, the procurement concerns buried in Slack, the legal escalation in Jira, and the product gaps discussed in call transcripts that actually determined the outcome.
Because retrieval is imprecise, teams over-index by stuffing the context window with every possible document to ensure the right one is in there. The result: thousands of reasoning tokens spent filtering noise. A world-class reasoning engine doing the work of a search index.
Failure Mode 2: "Lost in the Middle" (Attention Drift)
Research by Liu et al. (TACL, 2024) demonstrated that accuracy on multi-document reasoning tasks drops by more than 30 percentage points when relevant information is buried in the middle of a long context window. This matters enormously in enterprise environments, where critical signals are scattered across support escalations, pricing discussions, call transcripts, Slack threads, and CRM updates. Simply increasing context size does not solve the problem. In many cases, it amplifies it by forcing the model to attend to more noise.
Failure Mode 3: The Identity Crisis (Entity Disambiguation)
In a fragmented environment, identity is a variable, not a constant. "Jane Doe" in a Zoom transcript needs to resolve to the same Jane Doe in Salesforce, Gmail, Zendesk, Slack, and the CRM activity timeline. Without deterministic entity resolution, the model is forced to infer whether those interactions belong to the same person, account, or buying committee.
Without deterministic entity resolution, the model is forced to reconstruct identity probabilistically. A support escalation tied to one stakeholder, a pricing objection raised in a sales call, and an executive concern discussed over email may be incorrectly assembled into the wrong account narrative entirely.
Failure Mode 4: The Permission Ghost (Unauthorized Surface)
This is the silent killer of enterprise AI programs. Most RAG pipelines lack Source-System Parity. If the AI retrieves a snippet from a private executive email because it was "semantically relevant" to an intern's query, the system has failed regardless of whether anyone noticed.
Incidents like EchoLeak show exactly why retrieval-layer permission enforcement matters. In late 2025, researchers demonstrated a zero-click vulnerability in Microsoft 365 Copilot that could exfiltrate sensitive data from Copilot context without user interaction. No prompt injection required. The retrieval layer was the attack surface.
For most organizations, the permission layer isn't just a technical problem. It is an organizational liability that Legal and Security will eventually force you to solve on a deadline, under pressure, after something has already gone wrong.
The Production Wall
These four failure modes create the Production Wall. A curated demo can appear remarkably accurate. But production environments are not curated. They are noisy, fragmented, and constantly changing, with critical signals distributed across emails, calls, support threads, Slack conversations, and operational systems evolving in real time.
"You cannot solve these four problems by tuning the prompt. You have to solve them by fixing the context."

Section 3
The Deterministic Intelligence Layer
To climb over the Production Wall, enterprise architecture must evolve. The solution is not a larger context window or a more complex prompt. It is a fundamental shift in how data is prepared for the model. Enter the Deterministic Intelligence Layer: infrastructure that sits between your raw data silos and Claude, acting as the architectural antidote to the four failure modes in Section 2.
The Four Pillars
1. Precision Indexing (Ending the Token Tax)
Instead of relying on similarity search alone, the context layer resolves entities, removes duplication, and prioritizes high-signal interactions before retrieval. The model receives structured operational context rather than raw fragments competing for attention.
In Sturdy-observed deployments, replacing raw context with pre-indexed, distilled payloads has reduced token consumption by 80 to 90% on comparable workflows. Results vary by source data density and baseline architecture. You stop paying for Claude to be a search filter.
2. Signal Distillation (Solving "Lost in the Middle")
Semantic Pruning strips HTML headers, Slack noise, legal footers, and the RE: FWD: RE: reply chains that bury every actual decision in 40 lines of quoted text, distilling threads into thematic buckets: Bug Reports, Feature Requests, Sentiment Shifts. The most critical insights land at the beginning of the context window, bypassing the 30-point accuracy drop documented in long-context research.
3. Deterministic Entity Resolution (Fixing the Identity Crisis)
A Global Entity Map resolves disparate naming conventions into a single, immutable Customer ID. Claude is no longer guessing whether two conversations belong to the same account. It is being told they do.
4. Parity-Enforced Permissions (Exorcising the Permission Ghost)
The retrieval layer enforces source-system permissions before context assembly, so unauthorized records are excluded from the payload sent to the model. This is not a prompt-level instruction that can be overridden or confused. It is an architectural enforcement point that sits entirely upstream of the model.
Security becomes a structural property of the architecture, not a probabilistic instruction to the model. Incidents like EchoLeak show why this distinction matters: when permission logic lives inside the prompt, the retrieval layer remains an attack surface. When it lives at the data layer, it doesn't.
Reference Implementation: Sturdy + Claude via MCP
While the merits of this architecture are clear, building it internally results in years of maintenance debt (see Section 5). Sturdy leverages the Model Context Protocol to serve as the Context Engine for Claude, normalizing, indexing, and permission-stamping your customer intelligence layer across Salesforce, Gmail, Slack, and Zendesk before Claude ever queries it.
Claude provides the Reasoning Layer. Sturdy provides the Memory and Context Layer. Together, they move an enterprise from AI that reads your business to AI that acts on it.

Section 4
What It Unlocks: From Reading to Acting
In 2026, summarization is a commodity. The competitive advantage lies in moving from AI that reads your business to AI that acts on it. This transition requires a fundamental shift in how leadership views the AI stack and who owns what.
- IT, Data, and Platform Engineering provide the Engine (Claude): recurring operating expense. World-class reasoning, rented.
- RevOps, Data, and AI Teams provide the Map (the Deterministic Data Layer): a long-term asset. Customer intelligence, owned, not rented.
When the engine has a perfect map, the Acceleration Gap closes.
RevOps: The Revenue Architect
For the RevOps leader, a deterministic layer turns fragmented operational data into active revenue signals. Instead of building static dashboards that explain why a quarter was missed, RevOps can monitor the commercial signals that actually move deals: pricing hesitation in email, procurement delays, legal friction, competitive mentions, executive disengagement, stalled next steps, and tone changes across active opportunities.
A deterministic context layer resolves those signals to the right person, account, opportunity, and timeline before AI ever reasons over them. That is what turns scattered communication into reliable revenue action.
RevOps stops being a report generator. It becomes the operating system for revenue execution: designing the logic that turns verified commercial signals into coordinated GTM action.
Sales: Instant Account Intelligence
The average sales rep spends roughly 20% of their week on pre-call research. With a deterministic layer, the account briefing is no longer a probabilistic summary. It is a verified snapshot: "The customer's last three support tickets were resolved, but they haven't yet implemented the API update discussed in the March QBR."
Product: The Automated Feedback Loop
Product managers are often the most data-rich but insight-poor employees in the company. A deterministic layer moves PMs from reading feedback to querying insights. Claude analyzes 60 days of feedback across Slack and Zendesk and, with a single prompt, generates a high-fidelity Jira ticket including exact customer quotes, impacted account IDs, and revenue at risk.
Customer Success: Proactive Triage
In CS, latency is the enemy. A deterministic layer allows Claude to perform live triage. When a customer sends a frustrated email, the AI checks contract terms and recent product usage logs before the CSM has finished reading the subject line. It presents a Context-Aware Response ready to send, grounded in verified account data.
"The model you license today is rent. The customer intelligence layer you build is equity. One gets replaced. The other compounds."
Every account signal normalized, every entity resolved, every permission enforced. That accumulates. The organizations building this layer now are building institutional memory that makes every model they run on top of it better.

Section 5
The Build vs. Buy Reality
The instinct for most sophisticated IT and data teams is to build. It is a legitimate impulse. The stack looks deceptively simple: a few API connectors, a vector database, and some chunking logic. In the demo phase, an internal build often feels like the most cost-effective path.

The Four Hidden Engineering Hurdles
1. The Normalization Treadmill
Building a connector to Salesforce is straightforward. Maintaining the logic layer that resolves entity names across Salesforce, Slack, and Zendesk as those systems' schemas evolve is a full-time engineering job. This is Semantic Drift: hundreds of developer hours consumed by maintenance rather than innovation.
2. The Permission Mapping Paradox
Mapping row-level permissions from source systems into an AI context window is one of the most complex security challenges in modern software. Most internal builds rely on prompt-level security, which fails under the weight of incidents like EchoLeak. This isn't a technical trade-off. It is an organizational liability waiting to be forced into crisis.
3. The Latency Wall
A custom RAG pipeline often takes 5 to 10 seconds to fetch and clean data. In Sturdy-observed deployments, pre-indexed deterministic retrieval consistently operates under 1 second on production data volumes, but reaching that benchmark requires specialized search infrastructure expertise that is rarely the core competency of a generalist data team building from scratch.
4. The Token Optimization Tax
Without signal distillation, internal builds routinely pass 3x to 5x more tokens than necessary. Teams save on build costs only to spend twice as much on model API costs.
Where Does Your Engineering Dollar Go?
The strategic question isn't "Can we build this?" It's "Should we own the maintenance of this?"

Competitive advantage does not live in the plumbing. No customer chooses a vendor because their AI has a better Python script for cleaning Slack data.
By offloading the Normalization Treadmill to Sturdy, organizations are promoting their engineering teams from Data Cleaners to AI Product Owners, moving their best people away from the maintenance treadmill and toward the high-value work of building AI that drives revenue.
Buy the plumbing. Build the logic. The teams doing this are shipping revenue-generating AI workflows, while their competitors are still debugging entity-resolution scripts.
Section 6
What to Do Now: The 2026 Roadmap
The Acceleration Gap is not a permanent state. It is a choice of architecture. The move is not to wait for a smarter model. The move is to fix the context. Here are four moves for leadership to take in the next 90 days.
Move 1: Audit Your Retrieval Precision, Not Your Prompts
Most teams spend the majority of their time prompt-tuning errors caused by bad data retrieval. The action: Run a Ground Truth test. Take ten complex customer queries and manually check the data fragments Claude is being fed. If more than 20% of that data is noisy, stale, or misattributed, no prompt engineering will save the deployment. You have a plumbing problem, not a reasoning problem.
Move 2: Isolate a Multi-Source Workflow
The highest ROI for a deterministic layer is found where data is most fragmented. The action: Pick a high-value, closed-loop use case where data lives in at least three systems. For example: the path from customer feedback in Slack and Zendesk to an engineering action in Jira. Solve the context problem here, and you've built a blueprint for the rest of the organization.
Move 3: Enforce Permissions at the Data Layer
Stop treating security as a probabilistic instruction. The action: Move permission enforcement out of the system prompt and into the retrieval infrastructure. Ensure the retrieval layer enforces source-system permissions before context assembly, so unauthorized records never reach the model. The Permission Ghost is exorcised structurally, not instructionally, and the organizational liability is removed before Legal ever has to get involved.
Move 4: Define Where AI Earns the Right to Act
The distance between AI that summarizes and AI that executes is a trust gap, not a technology gap. The action: Build human-in-the-loop approval gates for high-stakes actions. Drafting a renewal contract. Creating a Jira ticket. Sending a support response. Use your deterministic layer to provide the required Confidence Equity. The threshold to target is a sub-5% error rate on AI-generated drafts. That is the point at which approval gates can be safely reduced, and workflows become self-sustaining.
Traditional probabilistic RAG architectures struggle to reach this threshold consistently at enterprise scale. Because probabilistic retrieval introduces entity errors, stale data, and permission noise, error rates on complex multi-source tasks typically stabilize in the 15 to 30% range regardless of prompt quality, even with hybrid retrieval and reranking layers added on top.
A deterministic layer that resolves entities before inference, distills the signal before retrieval, and enforces permissions before the model ever sees the data is the only architecture that makes sub-5% structurally achievable, rather than an occasional lucky outcome.
In Sturdy-observed deployments, teams that reach this threshold have consistently moved to reduced-oversight approval workflows within a quarter. Results depend on workflow complexity and baseline data quality. Reaching the sub-5% Trust Threshold is the definitive signal that an organization has graduated from "AI Experiments" to a Context Engine architecture capable of autonomous action. That is the architectural line between AI that assists and AI that acts.

Conclusion
The Architectural Advantage
Frontier models will continue to improve and commoditize. The durable advantage is no longer the model itself. It is the architecture surrounding it.
The long-term value does not live in another standalone AI interface. Interfaces change too quickly. The durable layer is the operational context infrastructure beneath them.
Organizations that solve deterministic context assembly, entity resolution, permission-aware retrieval, and operational state assembly gain a compounding advantage independent of whichever model, interface, or orchestration layer dominates next year.
Organizations that solve context architecture today are building infrastructure that compounds across model generations. As interfaces evolve and models improve, the operational context layer beneath them becomes increasingly valuable.
"The era of the Context Engine is here. Is your architecture ready for it?"

Executive Summary
The Context Engine
The model is not the problem. In every enterprise AI deployment that has hit a production wall in 2026, the failure lives one layer down: in how data is prepared, permissioned, and delivered before the model ever begins reasoning. Model choice has become the wrong question. With Anthropic's Claude surpassing OpenAI in U.S. enterprise adoption (34.4% vs. 32.3%, Ramp AI Index, April 2026), the market has already moved on. The competition has shifted from the Reasoning Engine to the Context Engine.
While nearly every enterprise has deployed frontier models, most are paying a Hallucination Tax they cannot see on their P&L. For an organization with 1,000 knowledge workers, the 4.3 hours per employee per week spent manually verifying AI outputs (Forrester, 2025) equates to approximately $16.8 million in annual salary drain, calculated at a conservative $75 per fully-loaded hour. Multiply that across a global enterprise, and it maps to the $67.4 billion in documented AI hallucination losses recorded in 2024 alone (AllAboutAI, 2025). This is not a failure of the model. It is a failure of architecture.
This paper argues that the next phase of enterprise AI requires a Deterministic Intelligence Layer: infrastructure that normalizes, indexes, and permissions customer data before it reaches the model. Teams replacing token-heavy RAG workflows with deterministic, pre-indexed context are seeing substantial reductions in cost per task while dramatically improving retrieval precision and AI reliability. More importantly, they are crossing the Threshold of Action: the point where AI becomes trustworthy enough to move from surfacing insights to executing workflows.
Section 1
The New Benchmark: Claude's Enterprise Breakout Moment
The AI market just had its crossover moment. As of April 2026, more U.S. businesses pay for Anthropic's Claude than for any other AI model. 34.4% vs. 32.3% for OpenAI, according to the Ramp AI Index, which tracks actual spending across more than 50,000 companies. This isn't a survey about intent. It's purchasing data.
By March 2026, Anthropic was capturing 73% of first-time business AI buyers (Axios, March 2026). A year earlier, one in 25 businesses on Ramp's platform paid for Anthropic. Today, it's nearly one in three.
Enterprise buyers don't switch defaults on a whim. They switch when something is demonstrably working better for the work they actually need done.
The Model Is Not the Problem
Here is the harder truth underneath that adoption story. Despite the crossover, most enterprise AI deployments are not delivering.
Widespread adoption. Widespread underdelivery. Both things are true simultaneously.
The instinct in most organizations is to treat this as a model problem: switch providers, upgrade to the latest version, hire a prompt engineer. None of it moves the needle in any sustained way, because the model is not where the failure lives. Claude is a reasoning engine. A sophisticated one. But a reasoning engine can only reason over what it's given. And in most enterprise deployments, what's given is a mess. Fragments.
The Performance Ceiling
Every technical leader deploying Claude at scale hits the same wall. The demo works. The pilot looks promising. Then it moves toward production, and something breaks. Not catastrophically, but consistently. The AI misattributes an item to the wrong account. It summarizes a customer's history using stale data. It generates an output that sounds authoritative and requires 20 minutes of human verification before it can be trusted.
"Feed a world-class reasoning engine confident, well-structured garbage, and you get the same in return."
This is not a failure of reasoning capability. It is a failure of context architecture. The data required to generate reliable outputs, account history, communications, support activity, call transcripts, and operational metadata typically exists across fragmented systems with inconsistent normalization, disconnected permissions, and no canonical entity resolution layer tying it together.
Context Is the New Infrastructure
The companies pulling ahead in 2026 are not winning because they chose a better model. They are winning because they solved the harder problem underneath it: delivering clean, resolved, permission-aware context before the model ever begins reasoning.
- IT, Data, and Platform Engineering provide the Engine (Claude): a recurring operating expense. World-class reasoning, rented.
- RevOps, Data, and AI Teams provide the Map (the Deterministic Data Layer): a long-term asset. Customer intelligence, owned.
Claude is the current catalyst. The model market will keep moving. New releases, new providers, new pricing. What doesn't move is the underlying problem: fragmented, unresolved, improperly permissioned data. Deterministic context is the durable architecture. The organizations building it now will carry that advantage into every subsequent model generation.
Most organizations already have the engine. What they lack is the map.
Section 2
The Hallucination Tax: Why Fragmented Data Kills AI Performance
If the model isn't the problem, why are so many production-grade AI initiatives hitting a performance ceiling? The answer is the Hallucination Tax.
In 2024, hallucinations cost enterprises an estimated $67.4 billion in global losses (AllAboutAI, 2025). By early 2026, the cost has shifted from outright fabrications to "silent hallucinations": outputs that look structurally perfect but are factually untethered from the current state of the business.
For an organization with 1,000 knowledge workers, the 4.3 hours lost per person per week equates to roughly 223,600 hours of wasted annual productivity, approximately $16.8 million in annual salary drain at a conservative, fully loaded rate. It never appears on the P&L as an AI cost. It shows up as underperformance, missed forecasts, and slower deal cycles.
This forces employees to act as "Human Middleware": the bridge between fragmented systems and the AI that was supposed to make them irrelevant. This tax is the direct result of four specific architectural failure modes.
Failure Mode 1: Retrieval Precision (The Token Tax)
Standard RAG is probabilistic. It retrieves semantically similar fragments, not operational truth. When a sales leader asks, "Why did we lose this seven-figure deal?", the system may surface an old QBR deck instead of the pricing objections in email, the procurement concerns buried in Slack, the legal escalation in Jira, and the product gaps discussed in call transcripts that actually determined the outcome.
Because retrieval is imprecise, teams over-index by stuffing the context window with every possible document to ensure the right one is in there. The result: thousands of reasoning tokens spent filtering noise. A world-class reasoning engine doing the work of a search index.
Failure Mode 2: "Lost in the Middle" (Attention Drift)
Research by Liu et al. (TACL, 2024) demonstrated that accuracy on multi-document reasoning tasks drops by more than 30 percentage points when relevant information is buried in the middle of a long context window. This matters enormously in enterprise environments, where critical signals are scattered across support escalations, pricing discussions, call transcripts, Slack threads, and CRM updates. Simply increasing context size does not solve the problem. In many cases, it amplifies it by forcing the model to attend to more noise.
Failure Mode 3: The Identity Crisis (Entity Disambiguation)
In a fragmented environment, identity is a variable, not a constant. "Jane Doe" in a Zoom transcript needs to resolve to the same Jane Doe in Salesforce, Gmail, Zendesk, Slack, and the CRM activity timeline. Without deterministic entity resolution, the model is forced to infer whether those interactions belong to the same person, account, or buying committee.
Without deterministic entity resolution, the model is forced to reconstruct identity probabilistically. A support escalation tied to one stakeholder, a pricing objection raised in a sales call, and an executive concern discussed over email may be incorrectly assembled into the wrong account narrative entirely.
Failure Mode 4: The Permission Ghost (Unauthorized Surface)
This is the silent killer of enterprise AI programs. Most RAG pipelines lack Source-System Parity. If the AI retrieves a snippet from a private executive email because it was "semantically relevant" to an intern's query, the system has failed regardless of whether anyone noticed.
Incidents like EchoLeak show exactly why retrieval-layer permission enforcement matters. In late 2025, researchers demonstrated a zero-click vulnerability in Microsoft 365 Copilot that could exfiltrate sensitive data from Copilot context without user interaction. No prompt injection required. The retrieval layer was the attack surface.
For most organizations, the permission layer isn't just a technical problem. It is an organizational liability that Legal and Security will eventually force you to solve on a deadline, under pressure, after something has already gone wrong.
The Production Wall
These four failure modes create the Production Wall. A curated demo can appear remarkably accurate. But production environments are not curated. They are noisy, fragmented, and constantly changing, with critical signals distributed across emails, calls, support threads, Slack conversations, and operational systems evolving in real time.
"You cannot solve these four problems by tuning the prompt. You have to solve them by fixing the context."
Section 3
The Deterministic Intelligence Layer
To climb over the Production Wall, enterprise architecture must evolve. The solution is not a larger context window or a more complex prompt. It is a fundamental shift in how data is prepared for the model. Enter the Deterministic Intelligence Layer: infrastructure that sits between your raw data silos and Claude, acting as the architectural antidote to the four failure modes in Section 2.
The Four Pillars
1. Precision Indexing (Ending the Token Tax)
Instead of relying on similarity search alone, the context layer resolves entities, removes duplication, and prioritizes high-signal interactions before retrieval. The model receives structured operational context rather than raw fragments competing for attention.
In Sturdy-observed deployments, replacing raw context with pre-indexed, distilled payloads has reduced token consumption by 80 to 90% on comparable workflows. Results vary by source data density and baseline architecture. You stop paying for Claude to be a search filter.
2. Signal Distillation (Solving "Lost in the Middle")
Semantic Pruning strips HTML headers, Slack noise, legal footers, and the RE: FWD: RE: reply chains that bury every actual decision in 40 lines of quoted text, distilling threads into thematic buckets: Bug Reports, Feature Requests, Sentiment Shifts. The most critical insights land at the beginning of the context window, bypassing the 30-point accuracy drop documented in long-context research.
3. Deterministic Entity Resolution (Fixing the Identity Crisis)
A Global Entity Map resolves disparate naming conventions into a single, immutable Customer ID. Claude is no longer guessing whether two conversations belong to the same account. It is being told they do.
4. Parity-Enforced Permissions (Exorcising the Permission Ghost)
The retrieval layer enforces source-system permissions before context assembly, so unauthorized records are excluded from the payload sent to the model. This is not a prompt-level instruction that can be overridden or confused. It is an architectural enforcement point that sits entirely upstream of the model.
Security becomes a structural property of the architecture, not a probabilistic instruction to the model. Incidents like EchoLeak show why this distinction matters: when permission logic lives inside the prompt, the retrieval layer remains an attack surface. When it lives at the data layer, it doesn't.
Reference Implementation: Sturdy + Claude via MCP
While the merits of this architecture are clear, building it internally results in years of maintenance debt (see Section 5). Sturdy leverages the Model Context Protocol to serve as the Context Engine for Claude, normalizing, indexing, and permission-stamping your customer intelligence layer across Salesforce, Gmail, Slack, and Zendesk before Claude ever queries it.
Claude provides the Reasoning Layer. Sturdy provides the Memory and Context Layer. Together, they move an enterprise from AI that reads your business to AI that acts on it.
Section 4
What It Unlocks: From Reading to Acting
In 2026, summarization is a commodity. The competitive advantage lies in moving from AI that reads your business to AI that acts on it. This transition requires a fundamental shift in how leadership views the AI stack and who owns what.
- IT, Data, and Platform Engineering provide the Engine (Claude): recurring operating expense. World-class reasoning, rented.
- RevOps, Data, and AI Teams provide the Map (the Deterministic Data Layer): a long-term asset. Customer intelligence, owned, not rented.
When the engine has a perfect map, the Acceleration Gap closes.
RevOps: The Revenue Architect
For the RevOps leader, a deterministic layer turns fragmented operational data into active revenue signals. Instead of building static dashboards that explain why a quarter was missed, RevOps can monitor the commercial signals that actually move deals: pricing hesitation in email, procurement delays, legal friction, competitive mentions, executive disengagement, stalled next steps, and tone changes across active opportunities.
A deterministic context layer resolves those signals to the right person, account, opportunity, and timeline before AI ever reasons over them. That is what turns scattered communication into reliable revenue action.
RevOps stops being a report generator. It becomes the operating system for revenue execution: designing the logic that turns verified commercial signals into coordinated GTM action.
Sales: Instant Account Intelligence
The average sales rep spends roughly 20% of their week on pre-call research. With a deterministic layer, the account briefing is no longer a probabilistic summary. It is a verified snapshot: "The customer's last three support tickets were resolved, but they haven't yet implemented the API update discussed in the March QBR."
Product: The Automated Feedback Loop
Product managers are often the most data-rich but insight-poor employees in the company. A deterministic layer moves PMs from reading feedback to querying insights. Claude analyzes 60 days of feedback across Slack and Zendesk and, with a single prompt, generates a high-fidelity Jira ticket including exact customer quotes, impacted account IDs, and revenue at risk.
Customer Success: Proactive Triage
In CS, latency is the enemy. A deterministic layer allows Claude to perform live triage. When a customer sends a frustrated email, the AI checks contract terms and recent product usage logs before the CSM has finished reading the subject line. It presents a Context-Aware Response ready to send, grounded in verified account data.
"The model you license today is rent. The customer intelligence layer you build is equity. One gets replaced. The other compounds."
Every account signal normalized, every entity resolved, every permission enforced. That accumulates. The organizations building this layer now are building institutional memory that makes every model they run on top of it better.
Section 5
The Build vs. Buy Reality
The instinct for most sophisticated IT and data teams is to build. It is a legitimate impulse. The stack looks deceptively simple: a few API connectors, a vector database, and some chunking logic. In the demo phase, an internal build often feels like the most cost-effective path.
The Four Hidden Engineering Hurdles
1. The Normalization Treadmill
Building a connector to Salesforce is straightforward. Maintaining the logic layer that resolves entity names across Salesforce, Slack, and Zendesk as those systems' schemas evolve is a full-time engineering job. This is Semantic Drift: hundreds of developer hours consumed by maintenance rather than innovation.
2. The Permission Mapping Paradox
Mapping row-level permissions from source systems into an AI context window is one of the most complex security challenges in modern software. Most internal builds rely on prompt-level security, which fails under the weight of incidents like EchoLeak. This isn't a technical trade-off. It is an organizational liability waiting to be forced into crisis.
3. The Latency Wall
A custom RAG pipeline often takes 5 to 10 seconds to fetch and clean data. In Sturdy-observed deployments, pre-indexed deterministic retrieval consistently operates under 1 second on production data volumes, but reaching that benchmark requires specialized search infrastructure expertise that is rarely the core competency of a generalist data team building from scratch.
4. The Token Optimization Tax
Without signal distillation, internal builds routinely pass 3x to 5x more tokens than necessary. Teams save on build costs only to spend twice as much on model API costs.
Where Does Your Engineering Dollar Go?
The strategic question isn't "Can we build this?" It's "Should we own the maintenance of this?"
Competitive advantage does not live in the plumbing. No customer chooses a vendor because their AI has a better Python script for cleaning Slack data.
By offloading the Normalization Treadmill to Sturdy, organizations are promoting their engineering teams from Data Cleaners to AI Product Owners, moving their best people away from the maintenance treadmill and toward the high-value work of building AI that drives revenue.
Buy the plumbing. Build the logic. The teams doing this are shipping revenue-generating AI workflows, while their competitors are still debugging entity-resolution scripts.
Section 6
What to Do Now: The 2026 Roadmap
The Acceleration Gap is not a permanent state. It is a choice of architecture. The move is not to wait for a smarter model. The move is to fix the context. Here are four moves for leadership to take in the next 90 days.
Move 1: Audit Your Retrieval Precision, Not Your Prompts
Most teams spend the majority of their time prompt-tuning errors caused by bad data retrieval. The action: Run a Ground Truth test. Take ten complex customer queries and manually check the data fragments Claude is being fed. If more than 20% of that data is noisy, stale, or misattributed, no prompt engineering will save the deployment. You have a plumbing problem, not a reasoning problem.
Move 2: Isolate a Multi-Source Workflow
The highest ROI for a deterministic layer is found where data is most fragmented. The action: Pick a high-value, closed-loop use case where data lives in at least three systems. For example: the path from customer feedback in Slack and Zendesk to an engineering action in Jira. Solve the context problem here, and you've built a blueprint for the rest of the organization.
Move 3: Enforce Permissions at the Data Layer
Stop treating security as a probabilistic instruction. The action: Move permission enforcement out of the system prompt and into the retrieval infrastructure. Ensure the retrieval layer enforces source-system permissions before context assembly, so unauthorized records never reach the model. The Permission Ghost is exorcised structurally, not instructionally, and the organizational liability is removed before Legal ever has to get involved.
Move 4: Define Where AI Earns the Right to Act
The distance between AI that summarizes and AI that executes is a trust gap, not a technology gap. The action: Build human-in-the-loop approval gates for high-stakes actions. Drafting a renewal contract. Creating a Jira ticket. Sending a support response. Use your deterministic layer to provide the required Confidence Equity. The threshold to target is a sub-5% error rate on AI-generated drafts. That is the point at which approval gates can be safely reduced, and workflows become self-sustaining.
Traditional probabilistic RAG architectures struggle to reach this threshold consistently at enterprise scale. Because probabilistic retrieval introduces entity errors, stale data, and permission noise, error rates on complex multi-source tasks typically stabilize in the 15 to 30% range regardless of prompt quality, even with hybrid retrieval and reranking layers added on top.
A deterministic layer that resolves entities before inference, distills the signal before retrieval, and enforces permissions before the model ever sees the data is the only architecture that makes sub-5% structurally achievable, rather than an occasional lucky outcome.
In Sturdy-observed deployments, teams that reach this threshold have consistently moved to reduced-oversight approval workflows within a quarter. Results depend on workflow complexity and baseline data quality. Reaching the sub-5% Trust Threshold is the definitive signal that an organization has graduated from "AI Experiments" to a Context Engine architecture capable of autonomous action. That is the architectural line between AI that assists and AI that acts.
Conclusion
The Architectural Advantage
Frontier models will continue to improve and commoditize. The durable advantage is no longer the model itself. It is the architecture surrounding it.
The long-term value does not live in another standalone AI interface. Interfaces change too quickly. The durable layer is the operational context infrastructure beneath them.
Organizations that solve deterministic context assembly, entity resolution, permission-aware retrieval, and operational state assembly gain a compounding advantage independent of whichever model, interface, or orchestration layer dominates next year.
Organizations that solve context architecture today are building infrastructure that compounds across model generations. As interfaces evolve and models improve, the operational context layer beneath them becomes increasingly valuable.
"The era of the Context Engine is here. Is your architecture ready for it?"
Our articles

The Scary Six: Contract Request

The second line of that image is a regular expression (aka regex). If your support or ticket system supports regex, try that search against the content of your tickets. You can probably hand this to your BI team, too. It will find customer comments like, “Hey, we’re just cleaning up some files, and can we get a copy of our agreement?”
For some background, at my last company, I had a standing meeting on my calendar every week to read random support tickets. From this, the concept of the “Scary Six” was born.
One of the Scary Six was a “Contract Request.”
At Newton, about 70% of the time, when a customer requested a copy of their contract, it was a risk to their revenue longevity. We audited them regularly and found they broke down into the following buckets:
We want to know when we can or how easy it is to cancel (50%).
We just need our contract because we lost it (30%).
We are getting bought, going out of business, etc. (10%).
We need to see if we can cut some costs (10%).
We saw this flag about once per 6,000 email conversations (.0167%). Generally, this average rings true for most businesses we work with today.
Combining these two metrics, we estimated that for every 10,000 email conversations, we received about 2 Contract Requests. In other words, for every 10,000 emails, we had 1.4 customers at risk.
Once we identified Contract Request as a revenue impact, our incredible CS team trained everyone to identify “Contract Request” language. We then built a process for addressing them.
The before/after impact of identification and triage was remarkable and resulted in doubling the retention rate for this signal.
Over the next few weeks, I will post the rest of the “Scary Six” with their regex. Those left on the list are “Executive Change,” “Renewal,” “Response Lag,” “Overpromised,” and obviously, “Cancellation.”
Please let me know if you have any other “Scary” triggers. I hope you give this a shot and find it illuminating.
.avif)
There's a New Sheriff in Town
When I started my first SaaS company, I had a standing meeting on my calendars every week to read random support tickets (random is the crucial word, by the way). Reading tickets was always illuminating and often painful. One of our learnings was a churn risk called "New Sheriff."
First, don't get me wrong, we trusted our team. But if there's one thing that always bothered me, I never really knew what our customers said about us. And, for that matter, what we were saying to them.
Eventually, we built a suite of search strings, and if you want to try some yourself, here are a few simple ones:
We would search for product issues with things like: "doesn't work"; "confusing"; "annoying" bug, and "clear cache."
Searching for things like "gotten back to me" and "still waiting" would indicate that our customer was still awaiting a response. I would look for revenue issues with: "new VP,"; "new vice president,"; "new manager,"; "has left the company,"; "copy of our contract,"; "renewal date," and "overdue."
You are probably thinking, "Why would I look for "new VP" or "new manager"?" It comes up like this, "Our HR Manager has left the company recently, and I need a login for our VP of HR, Jim Smith."
At Newton, HR executives were responsible for hiring/firing HR software decisions. We sold HR software.
A new HR executive was the highest indicator of churn in our business. By that, I mean, left unattended, our customer was almost certainly (80%+) going to churn at renewal. From this, the term "New Sheriff" was coined. A "New Sheriff" customer was no longer forecasted to be a long-term customer and thus needed to be resold.
We trained everyone at Newton on identifying a "New Sheriff" and where to send the alert - manually.
When we got a "New Sheriff" alert, several people got to work. The CS team would pull usage data and some other vital metrics. The account management team would reach out to identify the new VP and schedule a demo of our solution.
Our sales leadership would also reach out to the former executive. We'd offer to help them network to find a new job or make inroads at their new company.
In doing this, we turned our "churniest" event, one with an 80% churn rate, to one with a 30% churn rate (from -.8 to -.3). We also gained a lead for our sales team that closed 80% of the time (from 0 to +.8). In other words, we turned a very churny event into one that gained a half a customer.
If you'd like to capture "New Sheriffs," give me a shout, and I'll send you a few more advanced search strings. (If you’re a Sturdy customer, our models auto-flag this as “Executive Change.”)- Steve@sturdy.ai
.png)
The Rise of AI Operations Management
About the Author
Hi, I'm Steve Hazelton. I am one of the founders of a startup that helps businesses better understand their customers by using AI to identify risks and opportunities inside the unstructured data trapped in emails, chats, and phone calls. I received help writing this article by using generative AI for data collection (if you don’t know what that means, you are not alone, go here).
Caveat Emptor: Since I am the founder of a startup that relies heavily on AI to find happy and unhappy customers, I certainly have "bought in" to using AI for business to leverage untapped data streams. So, consider yourself warned. I also started my career a long time ago as a recruiter for technology companies, later built and sold an HR tech company, and later started an AI company…so the intersection of AI and career advice collide here.
Introduction
Often lost in this discussion of AI technology is the discussion of its impacts on our teammates and coworkers. What does the widespread adoption of AI in business mean for the careers of people who work at these businesses? While many of us are, and should be, concerned about job destruction, I want to talk about job creation.
Note: There is, at present, endless discussion on AI technology, which I won't bore you with here. If you want to learn about the different types of AI and AI tools, like Generative AI, Synth AI, Machine Learning, and others, you can read an article our co-founder wrote here.
From a career standpoint, the most significant change our businesses will see this decade is creating a new, high-paying job in AI Operations. This article will help you, the reader, define this role when you decide to hire this person, or if you desire to be that person, how to create the role in your company.
This person will leverage AI tools and products to improve a business's top and bottom-line revenue. They'll find revenue opportunities, prevent cancellations or churn, and make people more efficient. They will be indispensable.
Dan Corbin, an instructor at the Pragmatic Institute, states, "If you can change your mindset as a company and understand the capabilities of AI, this is where AI operations come in. You need this AI Operations Director to ask, "How do we tackle this from a macro level?" You must think about AI from an organizational perspective to leverage it to its full capacity."
We are at the beginning of a major, major shift in employment. Fifty years ago, did companies have an IT Manager? No, but they do now. Thirty years ago, did they have an e-commerce manager? Again, no, but they do now. Ten years from now, will companies have someone in charge of AI operations? Of course, they will.
Adoption is inevitable because the gains are too significant. As Mike Evans, Director of Customer Care and Analytics at Laerdal Medical, states, "You need someone to own this." Companies like MassPay have already implemented such a role, which they attribute to the 100% customer retention of their "Top 100" last year. Hawke Media, the top performance marketing agency in the country, shifted the purview of their existing Director of Business Intelligence to include AI Ops. They then improved revenue retention by 30% MoM in less than six weeks.
With that out of the way, let's get started.
The Role of a Director of AI Operations
As businesses continue to embrace AI technologies, the need for dedicated professionals to implement and oversee these systems will become critical. Enter the Director of AI Operations.
At its core, this role is creative: you need to think of new ways to solve old problems in ways that have never been done before. "How can we use tomorrow's tools to solve our problems today?" This is a key point. AI will help you solve problems in ways you never considered before because they were previously impossible.
The Director of AI Operations will be the key player responsible for developing, implementing, and managing AI strategies.
The AI Business Director should be able to create and implement an AI strategy that answers the following:
How can we use AI to find revenue opportunities?”
How can we use AI to identify and reduce revenue risks?”
How can AI make our teammates more efficient?”
This multifaceted role requires a deep understanding of AI vendors, data privacy, and a visionary mindset to leverage AI's potential effectively.
Note: This job does not require coding. This person isn't building AI; they are identifying the areas where AI can improve business performance.
Let's take a closer look at the responsibilities of this job:
Strategy Development: "What problems are we trying to solve?" The Director of AI Operations collaborates with various departments to identify areas where AI can be integrated to capture risk and opportunities or to improve efficiency. They create a comprehensive AI strategy aligned with the business's overall objectives.
Data Discovery: "What data could AI illuminate that we've previously been unable to use?" For example, a Director of AI Operations could use emails to create a new data stream that correlates customer product confusion with unhappiness and eventual cancellation.
Data Management: "What are the security, privacy, and regulatory challenges with our approach." AI heavily relies on quality data to make accurate predictions and decisions. The Director ensures that data is collected, cleaned, and stored securely. This person should be able to deep-dive on a vendor's privacy and regulatory compliance.
Implementation: "What systems will we need to leverage, and how will we accomplish this?" Once the AI strategy is in place, the Director oversees the implementation of AI projects, ensuring seamless integration with existing systems and addressing any technical challenges that arise. Just as important, this person will need to drive the "people-side" integrations and help people leverage these new data streams.
Performance Monitoring: "What are the success criteria?" Monitoring the performance of AI systems is critical. The Director tracks key performance indicators to measure the impact of AI applications and makes adjustments as needed. Critical here is to answer, "Is this driving the desired outcomes?"
Ethical Considerations: "Should we even use AI for this?" Some AI systems handle sensitive data and will replicate previous biases. A crucial question is, "Is the AI making decisions?" If "yes," then much thought should be put into whether or not AI is appropriate.
Growth of AI Jobs
According to a study conducted by the World Economic Forum, AI is estimated to create 58 million new jobs by 2024. This includes a wide range of roles, from data scientists and AI engineers to, of course, Directors of AI Operations. According to HireEZ, one of the world's largest outbound recruiting platforms, demand for AI-related positions has risen by 60% since 2021.
On the flip side of that coin, higher education and e-learning platforms are seeing a surge in interest in AI courses. Pablo Garcia, Content Lead at CXL, the top marketing e-learning platform, states, "CXL saw a much higher interest in AI courses among our students in 2023, with a 785% increase in engagement for the Advanced AI in Marketing course."
As more companies recognize the potential of AI and seek to stay competitive in the market, the demand for AI professionals is set to skyrocket. A survey conducted by Deloitte further reinforces the growing importance of AI in businesses. It revealed that around 61% of surveyed companies have already implemented some form of AI into their operations. That means 61% of respondents are looking to hire a Director of AI Operations if they haven't already. Don't get left behind.
Where to Start
If becoming your company's Director of AI Operations seems daunting, don't be discouraged if you don't have experience. Very, very few people do. Get started now, and you'll be far ahead of everyone else.
Where would I start? I would look at my current role and think, "How could AI help my current company keep customers longer? Or, how could AI make my group more efficient?"
What problems are we trying to solve?”
What data could AI illuminate that we’ve previously been unable to use?”
What are the security, privacy, and regulatory challenges with our approach?”
What systems will we need to leverage, and how will we accomplish this?”
What are the success criteria?”
Should we even use AI for this?”
Get on it! Also, if you’d like more help, download our AI Retention Plan & Calculator.
Are you looking to hire someone to manage AI Operations?
While writing this article, a friend sent me a job description for a “Head of AI Product Management” at a significant online streaming company. It pays 900k/year. Hmmm… A recent Sturdy poll on LinkedIn concluded that over 50% of respondents already have someone in an AI Operations position, with 25% looking to fill the role in 2024. If you’re interested in hiring for a Director of AI Operations, feel free to copy and paste the job description below:
Director of AI Operations
Role Overview: The Director of AI Operations will be the key player responsible for developing, implementing, and managing AI strategies. This multifaceted role requires a deep understanding of AI vendors, data privacy, and a visionary mindset to leverage AI's potential effectively.
Key Responsibilities:
- The Director of AI Operations collaborates with various departments to identify areas where AI can be integrated to capture risk and opportunities or to improve efficiency. They create a comprehensive AI strategy aligned with the business's overall objectives.
- Identify areas of improvement throughout the business and implement AI workflows.
- The Director ensures that data is collected, cleaned, and stored securely. This person should be able to deep-dive on a vendor's privacy and regulatory compliance.
- The Director tracks key performance indicators to measure the impact of AI applications and makes adjustments as needed.
- Once the AI strategy is in place, the Director oversees the implementation of AI projects, ensuring seamless integration with existing systems and addressing any technical challenges that arise.
- Stay updated with the latest generative and synthesis AI trends and technologies to ensure the company stays ahead of the curve.
- Develop AI strategy and roadmap and act as the foremost thought leader on ethical considerations such as how AI systems handle sensitive data.
- Train colleagues and other teams on AI workflows and best practices for their departments.
Requirements:
- Bachelor’s degree in Computer Science, Data Science, or a related field. Master’s degree preferred.
- Proven experience identifying areas where AI can improve business performance and executing those strategies.
- Strong analytical and problem-solving skills.
- Ability to work collaboratively with diverse teams.
- Excellent communication skills, both written and verbal.
As always, thanks for reading. Feel free to reach out to us to talk further.
Steve
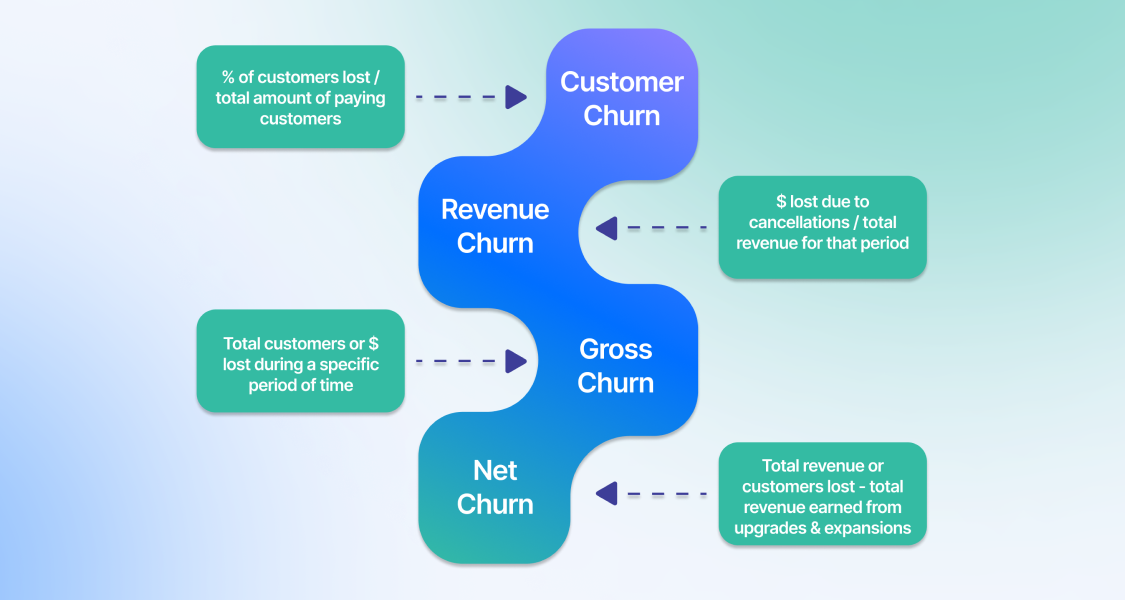
The four types of SaaS churn and how to calculate them

Customer churn is a term often used in the SaaS world, but what does it actually mean?
Simply put, churn is the rate at which customers are lost. These are customers that have canceled your service and aren’t coming back. It can be calculated for individual customers (B2C) or for an entire company (B2B). Four different types of churn are commonly measured: customer churn, revenue churn, gross churn rate, and net churn rate. Let's take a closer look at each type.

Customer Churn
Customer churn is the most commonly used type of churn. It is the percentage of customers that stopped using your company's products or services during a specific time frame. You can calculate your customer churn rate by dividing the number of customers you lost during that period — say a quarter — by the number of customers you had at the beginning of that period.
Let’s pretend for a moment that you work on the growth team at SaaS.io, a new (you guessed it) SaaS startup. Over the last few months, SaaS.io has continued to grow hand over fist with little to no customer churn. However, customer acquisition has begun to slow, and your boss is asking you to calculate the customer churn rate in October. This equation is relatively straightforward. At the beginning of October, Saas.io had 54 customers. However, by the end of the month, two had churned. That means your customer churn rate in the month of October was 3.7%.
1. Total customers at the beginning of a period: 54
2. Number of customers lost in period: 2
3. Customer Churn Rate = (2/54)*100 = 3.7% (that is a great number, by the way)
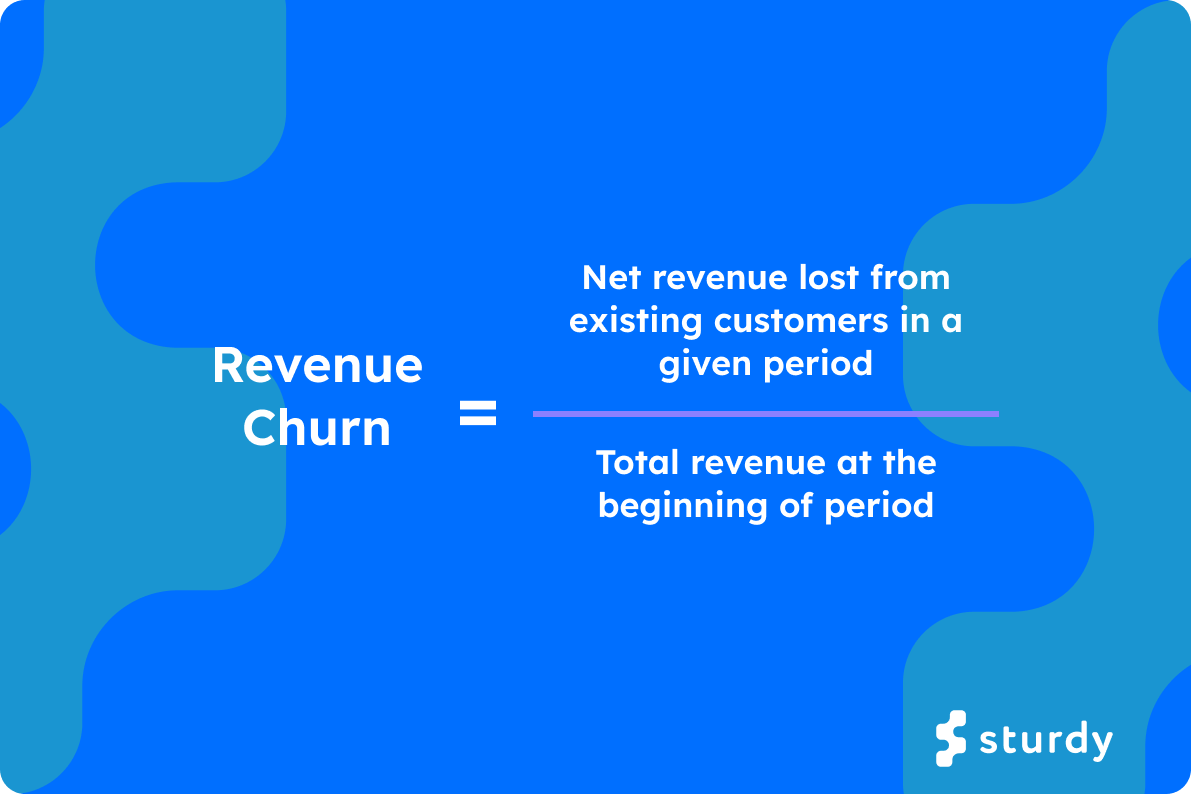
Revenue Churn
Revenue churn is similar to customer churn, but instead of measuring customers leaving the company, it measures the amount of revenue lost due to customers who have left or downgraded their plans. To calculate revenue churn, divide the total amount of revenue lost in a certain period by the total revenue at the beginning of that period.
If we head back to our SaaS.io example, it’s important to note that the October revenue churn is much scarier than the customer churn. Yes, only two customers churned, meaning there was a 3.7% customer churn rate. However, one of those customers (Customer 2) accounted for 11% of MRR (monthly recurring revenue). Customer 1 generated only $6,000 in MRR, whereas Customer 2 generated $22,000 MRR. That means that at the beginning of October, SaaS.io’s MRR was $200,000. By the end of October, the revenue churn was .14.
1. Total revenue at the beginning of a period: $200,000
2. Net revenue lost in period: $6,000 + $22,000 = $28,000
3. Revenue Churn Rate = $28,000/$200,000 = .14

Gross Churn Rate
The Gross churn rate takes into account both customer and revenue churn. It measures the total number of customers and revenue lost in a certain period, divided by the total number of customers and revenue at the beginning. This gives an overall picture of how much business is lost in a given time frame.
If we apply this to SaaS.io, the MRR for October was $200,000, and users canceled $28,000 worth of contracts. That means the gross churn rate will be 14%
1. Total revenue at the beginning of a period: $200,000
2. Net revenue lost in period: $6,000 + $22,000 = $28,000
3. Gross Churn Rate = ($28,000/$200,000) x 100% = 14%

Net Churn Rate
Net churn rate considers both customer and revenue churn. However, it also includes new customers and expansion revenue acquired in a certain period. Expansion revenue is the additional revenue you generate from existing customers through upsells, cross-sells, or add-ons. That’s why net revenue churn gives an overall picture of how much business is being gained or lost in a given time frame.
A month has passed since those two customers, and 14% of gross MRR was lost. Saas.io is currently at $172,000 MRR in November, as no additional sales have been made. Unfortunately, November has also seen $12,000 in contract losses. Luckily for Saas.io, a few existing customers have upgraded their plans, generating an additional $10,000 in revenue. Your boss asks you what the net churn rate for November is. First, you must subtract the customer upgrade revenue from the revenue lost in downgrades and cancellations. Then, divide that number by the revenue at the beginning of November.
1. Total revenue at the beginning of a period: $172,000
2. Net revenue lost in period: $12,000 - $10,000 = $2,000
3. Net Churn Rate = $2,000/$172,000 = 1.1%

Leaky Bucket Equation
At the beginning of this post, we noted that four types of churn could be measured. That isn’t entirely true, so here’s a bit of a bonus round. SaaS angel investor, Dave Kellogg argues that the leaky bucket equation “should always be the first four lines of any SaaS company’s financial statements.” Kellogg continues, “I conceptualize SaaS companies as leaky buckets full of annual recurring revenue (ARR). Every time period, the sales organization pours more ARR into the bucket, and the customer success (CS) organization tries to prevent water from leaking out”.
Kellogg defines the leaky bucket equation as “Starting ARR + new ARR - churn ARR = ending ARR”.
If we apply this to our Saas.io example, we can determine that the starting ARR in the fourth quarter (Q4) of 2022 was roughly $400,000. The new ARR in Q4 ‘22 was $56,000, and the Churn ARR in that same time period was $45,000. In other words:
1. Total starting ARR: $400,000
2. New ARR: $56,000 & Churn ARR: $45,000
3. Ending ARR = $400,000 + $54,000 - $45,000 = $409,000
Churn is an important metric to track for any SaaS company, as it can be used to identify trends, measure loyalty, and assess the effectiveness of customer retention strategies. Calculating churn rates can help companies identify which customers are more likely to leave and which types of customers are the most valuable. By understanding churn, businesses can take steps to improve customer retention and keep their business running smoothly.

Sturdy PX: Automatic Product Insights from Unstructured Data
We’ve learned from our own operational experiences as entrepreneurs, product owners, revenue leaders, advisors, and board members that for SaaS companies to remain competitive, customers must be at the center of product and go-to-market decisions. Every team needs to optimize to create end-user value. To understand what really creates end-user value, you have to listen to customers — closely. Unfortunately, listening to customers is harder than it sounds.
The volume and velocity of data that businesses are generating is mindblowing. Ironically, most of this data is unstructured and trapped in emails, support tickets, Slack, call transcripts, user communities, and survey results. Most product teams struggle to grasp this valuable “dark data” at scale. Some are starting to experiment with AI to make sense of user interactions. This has introduced two new big problems: getting data out of all these sources and the murkiness of the data itself. This is why we create Sturdy PX for product-oriented teams.
My guess is that forward-looking teams trying to use AI are running into the same big issues that we had to solve to get Sturdy in the wild — mainly data transformation. We’ve seen this called data munging. Yuck. Whatever you call it, data prep tasks are time-consuming and tedious. We’ve learned that teams spend an enormous amount of time on manual data wrangling, which slows access to the valuable stuff - the analysis and, ultimately, the insights! About 70% of our tech is dedicated to automating data preparation tasks. For example, most companies collect data in inconsistent data formats across multiple modes/data sources. Sturdy standardizes the data formats, cleans the data, and synthesizes it with structured data like CRM data.
Leveraging AI, we're transforming traditional product research by empowering anyone on a product team with self-service access to the unsolicited, unbiased, and unabridged voice of the user. Sure, surveys, prototype tests, focus groups, etc., are still in the mix. They should be. But we’ve found that getting a consistent stream of accurate, categorized, product and user-centric insights really scratches that itch that we’ve had as product people.
For a limited time, we’re offering Sturdy PX to qualified product teams for free. It’s easy to get started, and the not-free version is pretty darn affordable, even on a tight budget. Get Sturdy here.

Leveraging Unstructured Data: How Business Leaders Can Harness the Power of AI
Introduction:
In today's digital age, the sheer volume of data generated by businesses is staggering. Ironically, most of this data is unstructured and trapped in things like emails, support tickets, and phone calls. Until now, this meant that the only way to extract valuable insights was by using manual labor to categorize them.
This is where the power of Artificial Intelligence (AI) comes into play. By harnessing AI, business leaders can unlock the hidden potential of unstructured data and gain a competitive edge. In this blog post, we will explore how business leaders can effectively leverage AI to extract valuable insights from unstructured data and drive innovation.
Understanding Unstructured Data:
Unstructured data refers to any information that lacks a predefined data model or organization. It includes text documents, social media posts, images, audio, videos, and more. Unstructured data is generated in abundance from various sources such as customer feedback, emails, surveys, social media platforms, and help desk interactions. The true value of unstructured data lies in its ability to reveal patterns, sentiments, and trends that can shape business strategies.
AI and Unstructured Data: Extract, Diagnose, Proact:
Artificial Intelligence, particularly techniques such as natural language processing (NLP) and deep learning, can process and analyze unstructured data with remarkable accuracy. By utilizing AI, business leaders can transform this seemingly chaotic mass of unstructured data into actionable insights.
Information Extraction:
- First, AI removes the ”manual labor tax” associated with leveraging unstructured data. AI efficiently extracts relevant information from unstructured text data, at scale, for a fraction of the cost of manual processing. Text mining techniques, including entity recognition, sentiment analysis, keyword extraction, and topic modeling, can be used to identify critical insights buried within vast amounts of unstructured text. This information can be invaluable for market research, competitive analysis, and trend forecasting.
Knowledge Diagnostics:
- The next step after extraction is leveraging this data to diagnose risks and opportunities. AI converts unstructured data into a powerful diagnostic tool. Unstructured data sources like customer emails and chat transcripts contain valuable information about individual products and processes. For example, a business leader may realize that just one feature is causing the majority of customer unhappiness. They might realize that a certain Account Representative is very good at improving sentiment. The possibilities for improving our businesses are almost endless.
Proactivity and Prediction:
- The “holy grail” of unstructured data is leveraging this information and knowledge to proact on and predict future events. By analyzing historical unstructured data, leaders can identify issues and monitor them going forward. For example, data might reveal that customers are more likely to cancel within 6 months of having a leadership change event. Not only will AI help leaders identify this warning sign, but by analyzing unstructured data in real-time, it will warn leaders and provide them with the opportunity to save revenue.
In the era of big data, unstructured data holds immense untapped potential. Business leaders who harness the power of AI can gain a competitive advantage by extracting valuable insights from this wealth of unstructured information. From sentiment analysis and text mining to predictive analytics, AI techniques provide the means to unlock the hidden value within unstructured data. By embracing AI and leveraging unstructured data, business leaders can make more informed decisions, drive innovation, and stay ahead in an increasingly data-driven world.
AI is Transforming Product Management
Product management has evolved significantly over the years, adapting to customer expectations, increased competition, and technological advancements. What was once a fragmented and operational role is now one of the most strategic and cross-functional disciplines in many organizations. Modern product management has two key goals; delivering customer value and, subsequently, driving business growth.
In the past, product managers were often hardened SMEs relying on previous experiences and assumptions. However, in recent years, subject matter expertise has become less critical as the focus has shifted to better understanding a wide variety of users. Product managers now emphasize understanding customer needs, conducting user research, and gathering feedback to inform feature prioritization and, more importantly, the desired value-driven outcomes for customers.
These days, PMs have a massive amount of data at their disposal, enabling experimentation and validation. This iterative mindset helps mitigate risks, validate hypotheses, and optimize product features based on user feedback. And, to that end, user feedback is the key — the currency of modern product management feedback is what makes or breaks a product.
Traditional user feedback methods are a miss
Traditionally, user feedback has been gathered through surveys and customer interviews. Surveys are emailed to customers to gather feedback. Pretty straightforward. Customer interviews allow PMs to dig deeper into customer motivations, pain points, and specific use cases.
What do traditional product research methods have in common? They are labor-intensive, often expensive, and time-consuming, requiring reliance on other teams to complete. And, maybe the biggest drawback is that the data and insights generated are typically from a small subset of the product’s user base.
Welcome to the AI-era
AI-powered platforms are making it possible to sift through data using natural language processing (NLP) and machine learning algorithms to quickly analyze large amounts of customer-generated information like email, tickets, call transcripts, and more. These data sets have been nearly impossible to access in the past because of their unstructured nature. AI-based tools can search for patterns and recognize key signals that might be difficult and even impossible for humans to spot, especially at scale.
AI is catapulting PM teams into a new era by enabling them to quickly and accurately identify trends in user preferences and behaviors related to specific feature requests, common product defects, and areas the most prone to user confusion.
Additionally, AI-based platforms analyze vast amounts of data in real-time, helping product managers iterate and experiment faster while reducing costs and reliance on other teams. With the help of AI, teams can gain valuable, unbiased insights into their products more efficiently and more effectively than ever before.
Real use case examples are maturing
For example, product teams at HireEZ, the award-winning outbound recruiting solution, use Sturdy to slice and dice real user feedback like feature requests, confusion, and product friction by product mix, segments, and cohorts to understand better how to maintain product-market fit across their customer base.
Teams at MP, a leading provider of innovative HR technology and managed HR services, no longer rely solely on surveys and interviews to understand customers better. They use the real voice of the customer from email and support tickets to better identify opportunities to improve their offerings.
It’s no surprise that AI is transforming product management. The function was poised for evolution. AI is now simply accelerating more teams to become even more customer-focused, data-driven, collaborative, and iterative. Product managers are embracing digital transformation, agile methodologies, and a customer-centric approach to navigate complex market dynamics and deliver innovative products.

Your employees spend most of their workday searching for information and moving data from one place to another
In today's world, the power of AI is undeniable and, in many cases, is yet unknown. Businesses are leveraging this technology to increase their productivity and efficiency in ways that were never before possible. From semantic search to content generation, AI has enabled teams across the globe to work smarter, faster, and more effectively than ever before. But what really takes AI-powered productivity to the next level is converging information. Zeya Yan and Kristina Shen contend,
To date, generative AI applications have overwhelmingly focused on the divergence of information. That is, they create new content based on a set of instructions. In Wave 2, we believe we will see more applications of AI to converge information…While Wave 1 has created some value at the application layer, we believe Wave 2 will bring a step function change.”
In other words, this synthesis or convergence of information promises to revolutionize how businesses operate. In this blog post, we'll explore how much time teams are currently wasting with mundane tasks and how Synthesis AI can ameliorate that.
Before we do that, let’s first define what Synthesis or Applied AI is. In simple terms, it is the use of artificial intelligence (AI) in a practical context. It involves using AI algorithms and techniques to solve real-world problems or create new products or services by synthesizing vast volumes of data into insights. Examples include self-driving cars, facial recognition software, natural language processing, and machine learning. Applied AI can help businesses save time and money by automating routine tasks and providing better insights into customer behavior. For example, Sturdy is an Applied AI vendor using several AI techniques to help businesses understand and act on customer and prospect interactions more effectively.
Let’s take a deeper look at how Applied AI can power the productivity of your team. We’ll begin by taking a close look at the standard American work week. According to a 2023 Zippia study, the average American adult works 38.7 hours weekly. That is roughly 8 hours a day during the standard work week. There seems to be plenty of time to accomplish meaningful work, but there’s a catch. Workers spend more than half of their workday searching for information and doing manual data entry. A 2022 Coveo report found that “the average employee spends 3.6 hours daily searching for information.” The report highlights an increase in one hour per day over the last year, a “trend heading in the wrong direction.” Imagine the impact that has on your business. To keep the math simple, if you have 100 employees working 262 days a year, that’s nearly 100,000 hours of wasted time a year. And as the old adage goes, time is money.

But it doesn’t end there. Your employees spend nearly as much time simply moving data from one place to another as they are searching for information. A 2021 Zapier study concluded,
76% of respondents said they spend 1-3 hours a day simply moving data from one place to another. Additionally, 73% of workers spend 1-3 hours just trying to find information or a particular document.”
Put that into perspective for one moment. That means your workforce is potentially spending up to 75% of their time looking for information or moving data from one location to another. Thanks to AI, it doesn’t need to be this way.
.avif)
For example, Sturdy uses Applied AI to make data entry and searching for information unnecessary. Sturdy collects all unstructured interactions with your prospects and customers—the stuff stuck in various silos—emails, chats, tickets, call transcripts, etc. It cleans it up, synthesizes it with different data sources, and gets it into one searchable system every team will use. And let’s be honest, your business will never generate less data than it does now. With Sturdy, the dark data trapped in your business finds the people, systems, and teams that need it most without requiring data entry. Now organizations can route cancellation insights to account managers—surface unbiased feature requests to product teams—send bug reports to the engineering team, and more. Sturdy automatically delivers the insights to answer the “why?” and “what next?” to the teams and systems that need it most. Yesterday you searched for information. With Sturdy, it will find you.

How to Incorporate AI into Your Business Today
What is AI for business?
AI is not a fad. It’s the news. It dominates the talk of every business conference. And it is the number 1 topic of countless leadership meetings. CEOs are challenging their teams to leverage AI in every facet of their businesses to increase their productivity. gain deeper insights into user behavior, automate mundane tasks, and drive deeper insights with which to make critical decisions. It’s here. The big question is: How can you use it in your business right now?
GPT has catapulted AI into the spotlight, but does it translate into measurable productivity and revenue gains? A recent study by the National Bureau of Economic Research suggests that even in these early innings of AI for business, it’s moving the needle for early adopters.The study’s authors, Erik Brynjolfsson, Danielle Li Lindsey, and R. Raymond, concluded that AI “disseminates the potentially tacit knowledge of more able workers and helps newer workers move down the experience curve.” Our takeaway from the study is that AI is already helping humans do things faster with often better results.
AI provides businesses with numerous automation opportunities, which can help save time and money while increasing accuracy at the same time. Automation technologies such as natural language processing allow machines to interpret human speech or text input without any manual intervention required from humans. This eliminates tedious data entry tasks from employees’ workflows so they can focus their energy on higher-value activities. According to a recent Zapier study, “76% of respondents said they spend 1 - 3 hours a day simply moving data from one place to another. Additionally, 73% of workers spend 1 - 3 hours trying to find information or a particular document.” Additionally, automated processes reduce errors due to human factors like fatigue or distraction, which could otherwise lead to costly mistakes. The same Zapier study confirms this, arguing that “83% of workers said they spend 1 - 3 hours a day fixing errors.” That’s a full workday moving data around, looking for information, and fixing human errors. Imagine what you or your team could do with their day if that were a thing of the past.
The fact is that your company will never generate less data than it does now. The issue is that traditionally, 90% of data generated and collected by businesses is dark—untapped, and often completely unknown. Thanks to applied AI, companies can now use advanced algorithms to easily analyze large unstructured data sets, allowing them to understand consumer and customer behaviors better. This application spans the organization from marketing to engineering, product to customer experience, business intelligence to RevOps, etc. Imagine if these teams had their very own AI teammate that organized every interaction with your prospects and customers and turned it into knowledge and insights to help make everyone’s job easier. Now that’s possible with AI.
Harness the power of AI today. Simple, smart, and safe.
On a more grounded note, AI will have growing pains along the way. It has problems of its own, especially for businesses that need to leverage it to stay competitive.
It’s clear that adopting AI is no longer a question of “if” but “when.” It’s an opportunity facing every leader in every industry. And as we confirmed in our research for this report, there are huge incentives to move quickly. But before you leap into AI-powered solutions for your business, you must evaluate them properly—not only from a technical standpoint but also from a functional perspective.
Let’s be honest, millions of dollars will be wasted trying to “roll your own” AI. Before attempting a bespoke AI project, it is important to understand the challenges.
Cross-modal data integration
Cross-modal data integration refers to the process of combining and analyzing data from different modalities or sources, such as email, voice, chat, CRM data, ticketing data, and more. This is one of the biggest blockers for teams trying to build their own AI solutions. Cross-modal data integration aims to extract meaningful insights and knowledge from diverse data sources that may provide complementary or redundant information.
Cross-modal data integration involves several steps, including data preprocessing, feature extraction, alignment, and fusion, or what we call data joining. During data preprocessing, the data from each modality is cleaned, standardized, and prepared for the AI to analyze. Feature extraction involves extracting relevant features or characteristics from each modality, such as text features. Alignment involves mapping the features from each modality onto a common feature space, which enables them to be compared and combined. Finally, fusion involves combining the features from each modality to generate a unified representation of the data.
Cross-modal data integration is integral for AI for Business. For example, when you want to know the most commonly requested feature for a specific cohort of your customers, you need to combine data from multiple inboxes, systems, your CRM, and other modalities to provide a comprehensive and accurate answer.
Data cleansing and normalization
Data cleansing and normalization are critical steps in preparing data for AI applications. In simple terms—garbage in, garbage out. They are also insanely laborious. AI algorithms rely on accurate and reliable data to make predictions or generate insights. Data cleansing and normalization are critical to ensure the data used to train AI models is accurate, consistent, and complete. Think of it this way, you can improve the performance of AI algorithms by reducing noise like duplicate data and other inconsistencies. This can help AI models to make more accurate and reliable predictions. And cleaning and re-structuring data helps to make AI models more interpretable by reducing the complexity and variability of the data. This can help identify the most important features or variables driving the predictions or insights generated by AI models.
One of the most common reasons AI projects fail is due to data cleaning and normalization or, rather, the lack thereof. Business data can come in different formats, such as email, tickets, call transcripts, and more, each with unique characteristics and challenges. Normalizing and cleansing data across these different modalities is a complex task. Now consider that the amount of business data available for analysis is growing rapidly, making it difficult to manage and process data efficiently. This can be particularly challenging when cleansing and normalizing data, which can be time-consuming and computationally intensive.
To compound matters even more, business data is always stored in different systems or databases, which are infrequently compatible with each other. Just think how many different people are emailing your customers. Daunting.
Data cleansing and normalization are important but challenging steps in preparing data for AI applications. It requires domain expertise, technical skills, and a deep understanding of the data and the business problem.
User interface
Let’s say you can get clean, structured data into an AI or large language model. Now what? Now you need a user interface (UI), so business people can inform decisions and workflows with AI-generated insights. This isn’t trivial. You’ll need another team of developers because the people cleaning and preparing the data aren’t the same people who will build an end-user UI. Now you need to build some more software.
A well-designed UI helps users understand an AI system’s capabilities and benefits and increase their willingness to adopt and use it. The UI communicates the outputs and insights generated by the AI system in a way that is easy to understand and interpret. The UI can provide a way for users to input data, provide feedback, or customize the AI system to their needs. This can help improve the AI system’s accuracy and relevance and increase user value.
Data permissions
What next? Sigh. Don’t forget about data permissions. You are going to need them.
Data permissions refer to the rights and permissions required to access and use the outputs from your AI project. They are a critical component of data governance and must ensure that data is accessed per your organization’s policies. Think of this as who can see and use what.
Depending on the nature of the business and the data being used in the AI project, there will likely be requirements around data access and use. Ensuring that the AI project has appropriate data permissions can help to ensure compliance with relevant laws and regulations, such as data protection laws like GDPR.
Simply put, you must build more software to manage who can see what. Data permissions are often reviewed and updated to ensure ongoing compliance with and changing business needs, so your permissioning software has to be commercial grade.
Automations and exhaust
Insights from operational AI systems involve integrating AI models and insights into existing business processes and systems. You must get AI-generated insights to the humans and systems needing the knowledge. This may involve building APIs that allow the model to be called from other applications or systems or integrating the model into your teams’ existing tools like your CRM, email, etc.
Once the AI model is integrated, you have to automate the generation of insights. This may involve setting up automated alerts or reports triggered based on specific events or data conditions or integrating the insights into a dashboard that provides real-time insights (data UI).
By automating insights from AI systems, businesses can gain real-time, actionable insights that can inform decision-making and drive business outcomes. Automating insights can also help improve businesses’ process efficiency and effectiveness by reducing the need for manual analysis and decision-making. Vernon Howard, Co-Founder & CEO at Hallo, exclaims that with AI,
I can automate 20 to 30% of my work now.”
The takeaway is that if you can generate insights, you must autonomously get them to the right place.
Integration requirements
One of the main failure points for AI-related projects is unsustainable methods of extracting and converting data. In the past, this was done manually by interns, business analysts, and data engineers. Technological advancements like APIs make modern data capture processes instantaneously and consistently. This frees data and BI professionals from arduous entry work, focusing their efforts on more rewarding, core business responsibilities.
When selecting any technology solution, it’s important to ensure that it has integration APIs (Application Programming Interfaces) to enable seamless integration with your other systems and applications. Integration APIs allow different software applications to communicate with each other, exchange data, and perform tasks without the need for manual intervention.
Ideally, look for solutions that build direct integrations to platforms instead of using third-party integration platforms. Third-party platforms offer a fast way to connect systems but often lack configurability and data classification controls. Also adding a third-party data integration solution can also introduce another data processor to consider.
Data privacy
The subject matter experts we interviewed for this report agree that privacy concerns are the number one reason AI initiatives fail to launch. Xiaoze Jin, the Lead AI/ML Solution Architect at Rackspace Technology, states,
We’re in a very early inning of cloud AI as a SaaS offering. Privacy, above all else, is most important. Beyond privacy lies responsible AI/ethics, federated learning, and zero-trust framework security.”
Due to privacy concerns and stringent compliance regulations, functional leaders are often stymied by infosec and privacy teams reluctant to allow access to collect or process user data, preventing them from taking full advantage of AI-driven insights. Yacov Salomon, Founder & Chief Innovation Officer at Ketch, states,
Be aware of privacy, the ethical use of data, and the governance of data.”
He continues,
...the world is evolving, and if ML and AI are involved, you need to scrutinize. Governing around data makes a big difference.”
Data privacy laws are designed to protect individuals’ privacy and personally identifiable information (PII). PII refers to any data or information that can be used to identify a specific individual, directly or indirectly. PII can include any information that can be used to identify an individual, such as their name, email address, social security number, phone number, home address, date of birth, driver’s license number, passport number, biometric data, or any other unique identifier.
Any commercial AI solution should have a detailed and thorough approach to privacy. Ask for a copy. Otherwise, look for solutions that automatically de-identify data. The de-identification process can involve removing or masking certain data elements, such as names or addresses. Of course, there are different levels of de-identification, ranging from removing obvious identifiers to more advanced techniques that involve complex algorithms and statistical analysis. The effectiveness of de-identification methods depends on the type of data being processed and the acceptable re-identification risk threshold. Patricia Thaine, Co-Founder & CEO at Private AI, argues,
The easiest thing to do is remove PII as early as possible in the pipeline... At ingest or as soon as you possibly can in your system in order to minimize risk.”
Pro Tip: Sending customer data that includes PII to large language models (LLMs) like ChatGPT is a bad idea and will likely compromise user and confidentiality agreements with your customers.
Security
AI solutions may require access to sensitive data. Ensure that any solution provider maintains a comprehensive Information Security Management program to manage Sturdy’s systems and products’ security, availability, confidentiality, integrity, and privacy risks. The vendor’s program must be independently audited and certified to meet the requirements of Trust Services Criteria SOC2 Type II. You’ll also want to ensure that all data communications into and out of a platform are encrypted-in-transit. That data is stored encrypted-at-rest using industry-standard encryption mechanisms.
Any solution vendor should have a current SOC 2 Type II for your team to review. This is the most comprehensive SOC protocol and attests not only to the suitability of a vendor’s processes and systems but their operational effectiveness of sticking to those controls over a period of time.
Considering these technical requirements when evaluating AI solutions, you can ensure that the solution is compatible with your existing infrastructure and meets your performance needs.
AI is the future wave, and those who do not embrace this ever-evolving technology in their business are already falling behind. Jin argues,
We’ve already begun to see the paradigm shift, creating a new way of living and working with AI as a co-pilot... And yet, we’re still living in the wild west of AI, with land-grabbing occurring left and right.”
Those who do understand the immense power that AI can begin to automate processes, secure insights and increase customer engagement across multiple channels reap immeasurable rewards. As a CEO and business owner, Howard exclaims,
This is a big deal... this is huge.”
Unsurprisingly, AI has become one of the most aggressive sectors in business today. Still, fortunately, there are now plenty of resources and expert advice on how to safely and successfully deploy AI into your company. It’s time to get ahead of the competition and take advantage of this revolutionary force before it zooms us into an entirely new world of business opportunities!

Will AI take my job?
“100% of this article was written by a human” (True)
We’ve all seen large language models (LLMs) rapidly move into the mainstream, and many of us are already using them at present to generate blog posts, sales emails, and marketing campaigns (sadly, not yours truly).
Indeed, there is no shortage of ideas and blog posts explaining how businesses will use LLMs to generate content and remove routine or laborious tasks. Some say LLMs will render coders and lawyers obsolete. (BTW, they won’t). While there will certainly be job disruptions, we believe the change will be one of radical productivity improvement and, as a result, much more interesting and fulfilling work for many of today’s knowledge workers.
Before continuing, let’s clarify. LLMs are just one type of AI, a “tool.” If you think that auto-creating a sales email is a kind of “meh” endgame of billions of funding, you won’t hurt our feelings. That’s because we feel the future of AI in business will be utilizing many AI tools that will go far beyond creating content. They will help you think and take action. They will help you do things that are almost impossible or are very expensive to do today.
If you love manually updating JIRA with bug reports, typing QBR results into spreadsheets every Friday, or getting five people in a room to discuss your best customer, then the adoption of AI for your business is going to be a bummer. For the rest of us, AI will make us much more productive, informed, and, ultimately, employable.
Before continuing, I would like to say that I have spoken to many companies that have “started using AI in our business.” This always means dumping a healthy serving of emails and support tickets into GPT and generating summaries. And many now say, “That was cool, but now what?”
They’ve just scratched the surface. At the risk of sounding like an AI hype machine, answering “What’s next?” is really difficult because we’re still trapped in an impossibility box: today, there are things we think are impossible but aren’t anymore.
At Sturdy, business for AI will go beyond Generative AI, fundamentally changing how businesses collect, organize and synthesize their information. For now, I will call this AI Harmonization (AIH). Again, this goes far beyond writing sales emails. Beyond the LLM, AIH will illuminate previously dark sources of data and harmonize that information across other models, thereby creating previously unimaginable strategic visibility and scale.
The pieces of this AIH pie are the following:
- Collect and flatten metadata, structured data, and unstructured data into a privacy-compliant, permissioned, and normalized structure;
- Autonomously identify themes, topics, and insights inside this information and at its intersections.
- Automatically deliver “stuff” to, and synchronize with, other systems, workflows, and people who need it.
- All of the above will be done automatically, in real-time, without supervision.
- (extra credit): Your interface to this information will fundamentally change from “click here, then click here” to “tell me what you want.”
Of course, what I just laid out vastly simplifies the challenge. Yet, I can’t help but feel super excited about what it means…here are some examples:
If you are an Account Manager, your day might start with,
“Here are three accounts you need to look at right now.”
Or, let’s say you’re a VP of CS,
“Let me know anytime an enterprise customer has an issue within 90 days of their renewal date. Check this every day at 9 am.”
Or, imagine being a new VP of Products at a SaaS business,
“Every Tuesday, send me an XLS with a product roadmap with all bugs, organized by topic, reported by our enterprise customers worth more than 500k in ARR ranked by unhappiness generated and estimated engineering complexity.”
Sure, many of the examples above are already completed in many well-run companies today. They are just being done with manual labor. A lot of manual labor. In fact, our Sturdy data shows us that as much as 45% of an Account Manager’s day is data entry. Logging tickets, updating salesforce, writing call summaries (that number doesn’t even count the “account review” meetings).
Yes, AI will eliminate almost all this manual labor masquerading as knowledge work.
It will automate almost all data collection… reporting…and, eventually, much of the response.
But, worker productivity will skyrocket and allow our teammates to focus on much more meaningful tasks.
(Shameless plug: you could buy Sturdy today and next week 3 of the examples shown above are now part of your business. (What, you think I write blog posts for my health?))
In short, the people interacting on a day-to-day basis with customers will have about twice as much time to do high-value things, like talking to customers. If I had to guess, I would say that this probably means companies will have fewer Account Managers, but it also means that they’ll become twice as valuable (because they’ll be 2x more productive).
If you were hired as an Engineer in 1970, it is likely that for the first decade of your professional career, you spent your days using a slide rule to double-check someone else’s work. Did a computer take the engineer's job? No. Did their jobs get better, more productive, and more important? You betcha.
Let’s do this.
Your customers are already telling you what's going to happen.
Connect what customers say to why your numbers move. Contextual revenueintelligence, ready for any LLM — or running natively in Ask Sturdy from day one.